
AI promises to revolutionize the way we do science, which raises a central technological question of our time: Can classical AI understand all natural phenomena, or are some fundamentally beyond its reach? Many proponents of artificial intelligence argue that any pattern that can be generated or found in nature can be efficiently discovered and modeled by a classical learning algorithm, implying that AI is a universal and sufficient tool for science.
The word “classical” is important here to contrast with quantum computation. Nature is quantum mechanical, and the insights of Shor’s algorithm [1] along with quantum error correction [2,3,4] teach us that there are quantum systems, at least ones that have been heavily engineered, that can have trajectories that are fundamentally unpredictable1 by any classical algorithm, including AI. This opens the possibility that there are complex quantum phenomena occurring naturally in our universe where classical AI is insufficient, and we need a quantum computer in order to model them.
This essay uses the perspective of computational complexity to unpack this nuanced question. We begin with quantum sampling, arguing that despite clear quantum supremacy, it does not represent a real hurdle for AI to predict quantum phenomena. We then shift to the major unsolved problems in quantum physics and quantum chemistry, examining how quantum computers could empower AI in these domains. Finally, we’ll consider the possibility of truly complex quantum signals in nature, where quantum computers might prove essential for prediction itself.
Quantum Sampling
In 2019 Google demonstrated quantum supremacy on a digital quantum device [5], and in 2024 their latest chip performed a task in minutes where our best classical computers would take 10^25 years [6]. The task they performed is to prepare a highly entangled many-body quantum state and to sample from the corresponding distribution over classical configurations. Quantum supremacy on such sampling problems is on firm ground, with results in complexity theory backing up the experimental claims [7].2 Moreover, the classical hardness of quantum sampling appears to be generic in quantum physics. A wide range of quantum systems will generate highly entangled many-body states where sampling becomes classically hard.
However, quantum sampling alone does not refute the universality of classical AI. The output of quantum sampling often appears completely featureless, which cannot be verified by any classical or quantum algorithm, or by any process in our universe for that matter. For example, running the exact same sampling task a second time will produce a list of configurations that will appear unrelated to the original. In order for a phenomenon to be subject to scientific prediction, there must be an experiment that can confirm or deny the prediction. So if quantum sampling has no features that can be experimentally verified, there is nothing to predict, and no pattern for the AI to discover and model.
Quantum Chemistry and Condensed Matter Physics
There are many unsolved problems in quantum chemistry and condensed matter physics that are inaccessible using our best classical simulation algorithms and supercomputers. For example, these occur in the strongly correlated regime of electronic structure in quantum chemistry, and around low-temperature phase transitions of condensed matter systems. We do not understand the electronic structure of FeMoco, the molecule responsible for nitrogen fixation in the nitrogenase enzyme, nor do we understand the phase diagram of the 2D Fermi-Hubbard lattice and whether or not it exhibits superconductivity.
It is possible there are no fundamental barriers for a sufficiently advanced AI to solve these problems. Researchers in the field have achieved major breakthroughs using neural networks to predict complex biological structures like protein folding. One could imagine similar specialized AI models that predict the electronic structure of molecules, or that predict quantum phases of matter. Perhaps the main reason it is currently out of reach is a lack of sufficient training data. Here lies a compelling opportunity for quantum computing: The only feasible way to generate an abundance of accurate training data may be to use a quantum computer, since physical experiments are too difficult, too unreliable, and too slow.
How should we view these problems in physics and chemistry from the perspective of computational complexity? Physicists and chemists often consider systems with a fixed number of parameters, or even single instances. Although computing physical quantities may be extremely challenging, single instances cannot form computationally hard problems, since ultimately only a constant amount of resources is required to solve it. Systems with a fixed number of parameters often behave similarly, since physical quantities tend to depend smoothly on the parameters which allows for extrapolation and learning [8]. Here we can recognize a familiar motif from machine learning: Ab initio prediction is challenging, but prediction becomes efficient after learning from data. Quantum computers are useful for generating training data, but then AI is able to learn from this data and perform efficient inference.
Truly Complex Quantum Signals
While AI might be able to learn much of the patterns of physics and chemistry from quantum-generated data, there remains a deeper possibility: The quantum universe may produce patterns that AI cannot compress and understand. If there are quantum systems that display signals that are truly classically complex, then predicting the pattern will require a quantum computer at inference time, not only in training.
We’ll now envision how such a signal could arise. Imagine a family of quantum systems of arbitrary size N, and at each size N there is a number of independent parameters that is polynomial in N, for example the coefficients of a Hamiltonian or the rotation angles of a quantum circuit. Suppose the system has some physical feature whose signal we would like to compute as a function of the parameters, and this signal has the following properties:
- (Signal) There is a quantum algorithm that efficiently computes the signal. For example, the signal cannot be exponentially small in N.
- (Verifiable) The signal is verifiable, at least by an ideal quantum computer. For example, the task could be to compute an expectation value.
- (Typically complex) When the parameters are chosen randomly, the signal is computationally hard to classically compute in the average case.
If these properties hold, then it’s possible that no machine learning model using a polynomial amount of classical compute can perform the task, even with the help of training data.
The requirement of verifiability by a quantum process ensures that the signal being computed is a robust phenomenon where there is some “fact of the matter”, and a prediction can be confirmed or denied by nature. For example, this holds for any task where the output is the expectation value of some observable. The average-case hardness ensures that hard instances really exist and can be easily generated, rather than only existing in some abstract worst-case that cannot be instantiated.
There is a connection between the verifiability of a computation and its utility to us. Suppose we use a computer to help us design a high-temperature superconductor. If our designed material indeed works as a high-temperature superconductor when fabricated, this forms a verification of the predictions made by our computer. Utility implies verifiability, and likewise, unverifiable computations cannot be useful. However, since nature is quantum, a computation need not be classically verifiable in order to be useful, but only quantumly verifiable. In our high-temperature superconductor example, nature has verified our computer by performing a quantum process.
Making progress
John Preskill’s “entanglement frontier” seeks to understand the collective behavior of many interacting quantum particles [10]. In order to shed light on the fundamental limits of classical AI and the utility of quantum computers in this regime, we must understand if the exponential Hilbert space of quantum theory remains mostly hidden, or if it reveals itself in observable phenomena. The search for classically complex signals forms an exciting research program for making progress. Google recently performed the first demonstration of a classically complex signal on a quantum device: The out-of-time-order correlators3 of random quantum circuits [9]. We can seek to find more such examples, first in abstract models, and then in the real world, to understand how abundant they are in nature.
- Under widely accepted cryptographic assumptions. ↩︎
- Classical computers cannot perform quantum sampling unless the polynomial hierarchy collapses. ↩︎
- More precisely, the higher moments of the out-of-time-order correlator. ↩︎
References
[1] Shor, Peter W. “Algorithms for quantum computation: discrete logarithms and factoring.” Proceedings 35th annual symposium on foundations of computer science. Ieee, 1994.
[2] Shor, Peter W. “Scheme for reducing decoherence in quantum computer memory.” Physical review A 52.4 (1995): R2493.
[3] Shor, Peter W. “Fault-tolerant quantum computation.” Proceedings of 37th conference on foundations of computer science. IEEE, 1996.
[4] Kitaev, A. Yu. “Fault-tolerant quantum computation by anyons.” Annals of physics 303.1 (2003): 2-30.
[5] Arute, Frank, et al. “Quantum supremacy using a programmable superconducting processor.” Nature 574.7779 (2019): 505-510.
[6] Morvan, Alexis, et al. “Phase transitions in random circuit sampling.” Nature 634.8033 (2024): 328-333.
[7] Aaronson, Scott, and Alex Arkhipov. “The computational complexity of linear optics.” Proceedings of the forty-third annual ACM symposium on Theory of computing. 2011.
[8] Huang, Hsin-Yuan, et al. “Provably efficient machine learning for quantum many-body problems.” Science 377.6613 (2022): eabk3333.
[9] Abanin, Dmitry A., et al. “Constructive interference at the edge of quantum ergodic dynamics.” arXiv preprint arXiv:2506.10191 (2025).
[10] Preskill, John. “Quantum computing and the entanglement frontier.” arXiv preprint arXiv:1203.5813 (2012).
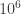 gates—
gates—