In my closet, in a basket labeled “Random stuff,” sits a bag of quarters. They total only a few dollars, but their worth to me exceeds their monetary value. I received the quarters from Mark Wise.
Mark taught a course about the Standard Model of particle physics at my master’s program at the Perimeter Institute for Theoretical Physics, near Toronto. Perimeter borrowed him from Caltech, to whose faculty he belonged. Mark had grown up in Canada and studied at the University of Toronto; so he didn’t mind visiting Canada even in the depths of winter.
What would Mark have minded? He projected a mild manner—an innocuousness—that suited his sense of humor, which he often directed at himself. Mark had a bald patch and glasses, and he wore a mustache. Physics jokes and science-fiction references decorated his T-shirts, one of which he wore beneath a black suit jacket to our first class. His voice was nasal; it grated a little. But I relished listening to Mark’s lectures.
Mark’s lecturing exemplified clarity, because he knew particle physics so deeply. When he walked us through its Lagrangians and scattering diagrams, his conclusions seemed inescapable. His lectures’ logic and structure appealed to me as someone who’s been hyper-organized since at least fourth grade.
Yet Mark cared about us students beyond the requirements of pedagogy. His T-shirts invited conversation from those who arrived to class early. Whenever a student answered or asked a question, he tossed them a quarter. Sometimes, he’d pause to examine the quarter, deliberate about whether to toss a Canadian quarter or an American one, or opine about the motto printed on the coin. (Mark confessed to having lower standards than those ingrained in the New Hampshire state motto, “Live free or die.” Where he came from, “We just wanna live!”)
Some days, Mark found little change in his pocket and announced that he needed to return to the bank for more quarters. The announcements sounded like complaints. He didn’t need to return to the bank, though, as nobody needs to bring doughnuts to the office for sharing.
I discovered the icing on the doughnut two years later, as a PhD student at Caltech. I sat in on part of a quantum course taught by Mark. To every student who completed the course, Mark gave a T-shirt that read, “Licensed quantum mechanic.” I received a T-shirt, although I only sat in on part of the course. I’ve never worn it, because I’ve wanted never to wear it out.
In 2024 and 2025, I co-taught a course on quantum-steampunk creative writing. Students learned about quantum physics, quantum technologies, and thermodynamics. Quanta are discrete units. For example, a photon is a quantum of energy. I illustrated quanta with coins, which are discrete units of money. From then on, I tossed a quarter to every student who answered or asked a question about quantum physics. (I joked that I should have tossed pennies, the minimal units of money, but chose quarters because inflation had been high recently.) I adapted Mark’s tradition to thermodynamics—the study of energy—by tossing Hershey’s kisses—dense packets of energy.
Before moving out of Caltech, I said goodbye to Mark. He worked among the high-energy theorists, rather than the quantum information or condensed-matter theorists, so I had to hunt down his office. He smiled and made a joke, of course.
Mark passed away this summer. His Caltech colleague John Preskill published a eulogy as a blog post here. (I learned from John’s post that inflation led Mark to upgrade his quarters to dollar coins. So much for feeling generous about upgrading from pennies to quarters.) When asked about the student experience at Caltech, Mark would say, “Caltech is heaven for professors.” Irony would creep into his voice and body language as he’d continue, “Doesn’t that mean it’s heaven for students, too?” I worked my rear off as a student at Caltech and Perimeter, but I’d call both environments fairly heavenly. Mark and his ilk are reasons why.
Mark Wise, the John A. McCone Professor of High Energy Physics at Caltech, passed away on July 10 at age 72. At a recent memorial service, John Preskill made these remarks.
I’m John Preskill, Mark’s colleague on the Caltech physics faculty for more than four decades. Our friendship goes back even farther. My wife Roberta and I met Mark and Jackie not long after they arrived at Harvard in 1980. We’ve been friends since then. We attended the bris for both Barry and Jonathan during those Harvard days. Mark and Jackie have two boys and we have two girls who are a few years younger, who were thrilled to connect with Barry and Jonathan when the families would get together for occasions like Passover or Hanukkah or Thanksgiving. When the kids were little, Mark and I would sometimes muse about the potential for forging even closer family ties if those relationships blossomed.
That didn’t happen. But Mark would preside at each Seder with a light hand, sprinkling the occasion with corny jokes as was his style, and Jackie would be determined to make it to the end of that customized family-friendly Haggadah she had meticulously prepared. The children, meanwhile, would be wondering when they’d be able to continue their game of sock baseball.
Many of you know that Mark was deeply dedicated to his family and friends. I’ll make some brief remarks about three facets of Mark I know especially well: Mark the scientist, Mark the teacher and mentor, and Mark the colleague and friend.
Because of his self-deprecating manner, those of you who are not scientists may not appreciate Mark’s stature as a physicist. He was one of the most influential figures in theoretical particle physics of his generation. It was not obvious things would turn out that way. Growing up in Toronto, Mark was an indifferent student, and his poor grades reflected that lack of interest. As a 9th grader, though, it struck him that he better change his ways and figure out how to make something of his life. He liked sports — the possibility of being a professional athlete was briefly considered, but discarded. Somehow he decided that science would be a better fit. I’m not sure why — he had recently failed math. But he worked hard and had inspiring teachers, so by the time he finished high school Mark was an excellent student, and he sailed into the University of Toronto well prepared to major in physics,
At U of T, Mark came under the influence of a young professor, Nathan Isgur, who would later become his close research collaborator. Under Nathan’s guidance, Mark sought admission to the PhD programs of the most prestigious US research universities, intent on a career devoted to deep exploration of the fundamental laws of physics. He was rejected everywhere he applied. He should have been discouraged. But he wasn’t. Mark shrugged and said: “It’s okay. I’ll stay another year in Toronto, I’ll get a master’s degree, I’ll apply again and I’ll get in somewhere.” And that’s what happened. He went to Stanford, where, under the kind tutelage of Fred Gilman, Mark took off like a rocket. Hired to the Caltech faculty in 1982, he was a tenured full professor three years later at the age of 31, and appointed as the John A. McCone Professor of High Energy Physics while still in his 30s.
Mark liked action movies, such as those starring Arnold Schwarzenegger or Clint Eastwood. In serious moments, we would sometimes ponder together why we’re successful at what we do, and Mark would always quote Clint Eastwood as Harry Callahan in Magnum Force: “A man’s got to know his limitations.” We would both laugh, but those were words of wisdom. Mark understood what he did well as a research scientist and what he was less good at. Finding problems he could solve that would have interesting consequences for experiments that had been done or could be done was where he excelled – he did it again and again. Mark never lost his zest for calculating things, often by hand with pen and paper, his head resting on one arm with his glasses pushed up onto his forehead as he scribbled. Getting to an answer that was experimentally relevant never stopped giving him a thrill.
Mark also never lost his sense of appreciation for the teachers and mentors who had inspired and helped him. Perhaps that’s why he became such a dedicated teacher and mentor himself. It’s hard to impress Caltech students, but Mark’s lectures where extremely popular, not just for their pedagogical value but also for the humanity and humor he displayed. Students had to pay attention because otherwise one might miss the jokes, which inevitably became known as “Wisecracks.” There is even an account on X with the handle @MarkWiseSays, curated by students who want to preserve Mark’s pithy lessons in physics and in life.
For example, Mark might say: “If you really get depressed, I recommend diagonalizing a 2×2 matrix.” For physics students, this is both funny and sage advice. Or he might say. “This calculation will knock your socks off.” A cliché you might hear from anyone. But who besides Mark would then proceed to remove his shoes, rip off his socks, hurl them at the blackboard, put his shoes back on and resume lecturing?
Most famously, Mark would come to class with an ample supply of coins. He would ask the class questions, sometimes about physics and sometimes random trivia, rewarding a student who gave an answer Mark approved of by tossing a coin. At first the coins were quarters. But Mark, who had a scholarly interest in finance as well as physics, eventually felt that due to inflation he needed to upgrade to dollar coins. These are harder to come by, so it took frequent visits to the bank to make sure he wouldn’t run out. His antics in class made Mark human and approachable, and students responded. Mark felt that many Caltech students don’t fully realize how smart they are. He saw part of his job as building their self-confidence and relieving their stress.
As a colleague and mentor to graduate students and postdoctoral scholars, Mark was highly collaborative. He believed that interactions with others sparked his creativity. He was never at all pompous. I know this started early. When we were in the Harvard Society of Fellows we were obligated to have dinner with the Senior Fellows on Monday nights. It was a rather stuffy occasion. And, though I don’t think they do this anymore, after a sumptuous meal we would literally retire for brandy and cigars. Once, while puffing on his cigar after dinner, Mark had an inspiration. He gathered up a few junior fellows and led them to a theater for a movie he thought everyone should see right away. The movie was Conan the Barbarian. And everyone had a blast. That was a perfect Mark moment.
As the news about Mark has spread, accolades have poured in from physicists all over the world. He was admired not just for his scientific brilliance, but almost as much for his quirky sense of humor and his kindness. Mark was a wonderful friend to many of us. When you were with him, you were sure to laugh and feel good. He touched the lives of countless colleagues, students and friends. We miss him terribly but there are so many memories that we’ll cherish. We are all so very fortunate to have known and loved Professor Mark Wise.
A scientist in Florence can’t avoid bumping into colleagues.
When visiting the Renaissance’s birthplace last summer, I ran into a fellow physicist even on a Saturday morning. I was wandering around the Uffizi Gallery, a museum blessed with some of the greatest hits in western art. A familiar face arrested me on the first floor.
Another colleague cropped up outside the museum. (Some might classify him as an applied physicist or an engineer, but he exhibited a theoretical physicist’s overactive imagination.)
One colleague, I’d been looking forward to meeting for over four years. Jae Dong Noh is a professor of physics at the University of Seoul in South Korea. He’d conducted the first numerical tests (classical-computer simulations) of an idea I’d helped midwife, the non-Abelian eigenstate thermalization hypothesis (NAETH). An earlier blog post described this mouthful, which predicts how certain quantum many-particle systems thermalize, or experience the flow of time. These systems’ dynamics conserve properties, analogous to energy, that are incompatible: one can’t measure the properties simultaneously, as one can’t measure a quantum particle’s position and momentum simultaneously. Because incompatibility helps distinguish quantum from classical physics, such systems’ thermodynamics qualifies as particularly quantum.
Jae Dong modeled such a system and others numerically in a paper. I admired his computational techniques and his grasp of symmetries (for experts: how non-Abelian symmetries affect chaotic quantum systems’ energy-level statistics). My postdoc Aleks Lasek was planning a more thorough numerical test of the NAETH, so I reached out to Jae Dong, and a collaboration crystallized.
Seoul operates thirteen hours ahead of Maryland, but we managed to Zoom because Jae Dong is a night owl and I’m an early bird.1 Zoom introduced me to a man perpetually dressed in a neat button-down shirt and sweater, silver overriding the black in his hair. The neatness extended to Jae Dong’s explanations: if Aleks and I didn’t understand one of his emails, he’d explain it quietly and calmly, untangling the confusion as though pulling a comb through wool.
The collaboration settled into a rhythm: I’d pose a question or propose a goal, Jae Dong would respond with an analytical calculation,2 I’d find holes in the calculation, Jae Dong would plug the holes, I’d re-check the argument’s logic, and we’d repeat the cycle. Had I been in Jae Dong’s shoes, I’d have swallowed the constant objections as I’ve swallowed grape-flavored cough medicine,3 but he always responded with equanimity—sometimes even good cheer—and a possible solution. Meanwhile, Aleks and then-undergraduate Jade LeSchack checked our analytical arguments numerically.
Florence flaunted a little steampunk during my visit.
So smoothly did the collaboration hum along that we coauthored two papers before ever meeting in person. One demonstrates numerically that two quantum many-body systems (for experts: nonintegrable Heisenberg models) obey the NAETH.4 In the other paper, we derive a symmetry relation from the NAETH. If the 17-syllable NAETH is a mouthful, the symmetry’s name is half a mouthful: a Kubo–Martin–Schwinger (KMS) relation. It’s important because (i) it enables us to calculate how rapidly a thermodynamic system responds to a stimulus, such as a weak magnetic field, and (ii) physicists go gaga over symmetries generally.
The KMS relation constrains thermal states—essentially, systems that have temperatures. Your typical isolated many-particle quantum system looks thermal if you can observe just a small chunk of it at a time. Accordingly, Jae Dong and collaborators had proved that isolated many-particle quantum systems obey the KMS relation approximately. The larger the system, the more accurate the approximation.
We extended his argument to systems whose dynamics conserve incompatible properties. Such an extension might sound simple, but its proof filled 24 pages of appendices. (For experts: Clebsch–Gordan coefficients are tricky blighters.) We discovered that, under certain conditions, incompatible conserved quantities can reduce the extent to which a quantum system obeys the KMS relation. Quantum incompatibility can augment deviations from conventional thermodynamics.
Italy’s architecture impressed me.
Jae Dong planned to present about our work at StatPhys, an international statistical-physics conference, which Florence was hosting in 2024. Throughout the two-and-a-half months before the conference, the KMS relation consumed our team. (For experts: Clebsch–Gordan coefficients are very tricky blighters.) I even hid in my hotel room, working and reworking our proofs, during another conference during that time.
The toil paid off. We submitted our KMS manuscript for public scrutiny the day I flew to Florence—because not only Jae Dong would be representing our team at StatPhys. I was looking forward to meeting him there for the first time.
A corner of the hall where the StatPhys opening ceremony took place.
The StatPhys committee outdid itself. The opening ceremony unfolded in Florence’s Palazzo Vecchio, where members of the Medici dynasty once lived. Giorgio Parisi, who won a Nobel Prize for statistical physics in 2021, lectured at the ceremony.
Giorgio Parisi, with another history maker.
The meat of the conference took place in two other palaces, the Palazzo dei Congressi and the Palazzo degli Affari. In one of them, I met Jae Dong. Although we’d shown that quantum incompatibility can defy thermodynamic predictions, he met my expectations.
We discovered another thermodynamic phenomenon challenged by incompatible conserved quantities, so stay tuned for another paper and blog post. Some colleagues, one can’t avoid; others are worth engaging with again and again.
1 Aleks has confessed to night-owl habits, but physics motivates him to adapt. Some days, he’s emailed me results before even I’ve woken up. Who needs coffee when the thrill of discovery electrifies one minutes after one hops out of bed?
2 An exact calculation written out on paper, as opposed to a numerical, or approximate, calculation performed by a silicon-based classical computer.
3 Does anyone like the grape flavor? Why do companies bother producing it?
Your inbox registers an email from the chair of a faculty-hiring committee. With trembling fingers, you click on the message. “We’ve been grateful for the opportunity to learn about your work…The decision was very difficult…many highly qualified candidates…” Months of labor, soul-searching, strain, and anxiety give way to despair. The committee has filled the position, and not with you.
I recently published advice about how to proceed if you receive an offer of a faculty position. But what if you don’t receive an offer—what if hiring committees reject you? Or scholarship committees, grant committees, admissions committees, or potential advisors? What if a journal referee shreds your magnum opus? Or a program committee declines your submission to a conference?
Failure suffuses science as dinner suffuses a nighttime diaper, for two reasons. First, undertaking science is difficult. By “undertaking science,” I mean formulating and proving theorems, cajoling equipment into working, identifying bugs in code, extracting meaning from noisy data, etc. Second, science doesn’t unfold in a vacuum. Human beings do science within a society fraught with opinions, emotions, and limited resources. These challenges lead to the failures and rejections that this article addresses most. (If you’re a member of my group and you’re facing a failure due to the difficulty of undertaking science, come talk with me.)
What can you do if failure or rejection ails thee? The rest of this article prescribes, in chronological order, steps that will help you recover. You can even turn your lemons into, if not lemonade, then not-entirely-unappetizing lemon meringue pie.
“O what can ail thee, knight-at-arms, alone and palely loitering?” “The scientific life is rough.”
Immediately after receiving the news:
Read the communication once—or, if you must, twice. Don’t linger over the letter for longer than necessary.
Put the communication away, so you won’t see it unless you try to. If the news came via email, remove the message from your inbox.
Lower your heart rate. Electrified with anger? Expend that energy; go for a walk, for a run, or to the gym, if possible. If you can’t, breathe deeply for several minutes, extending your exhalations.
Review records of your successes. I maintain a folder called “Nice messages.” It contains notices of awards I’ve received, kudos on papers I’ve published, messages such as “Thanks for everything this past semester! Your class was probably my favorite one,” and every compliment I’ve received from the taciturn John Preskill via email. Review evidence—remind yourself—that you’re not a failure even though you’re experiencing failure or rejection.
Avoid thinking about the news for a few days. Imagine cutting yourself on a kitchen knife. The wound may sting and bleed initially. But the blood clots and the stinging diminishes if you cover the wound and don’t aggravate it.
After experiencing a failure or rejection, invite a colleague to lunch, and ask about their recent reading and travels. Dive into a project that will absorb you. Visit a museum, or watch a movie. Remove the letdown from your thoughts.
Consider seeking input from a mentor, especially if you’ve never experienced a failure or rejection of this type before. Mentors have more experience and so can put obstacles in perspective. For example, suppose you’re a student who’s received an upsetting referee report from a journal. The report might look mild to a faculty member, who’s likely received far more, and more-upsetting, reports. What sounds harsh to you might sound quotidian to an advisor, whose lack of distress might reassure you.
Also, mentors notice upsides that you’ve overlooked. Perhaps the referee trashed your presentation of an idea but tacitly approved of the idea itself. The trashing might have drowned out the approval during your reading. Yet the approval could justify a resubmission to the journal, upending your belief in the cause’s hopelessness. Relatedly, a mentor can help you identify strategies for moving past the failure. Maybe this journal won’t publish your paper but another journal is soliciting contributions to a relevant special collection.
As a PhD student, I applied for an internship at a company developing a quantum computer. I broke an obligation and flew out of state to interview for the position. No offer materialized. To process the outcome, I spoke with a more-advanced researcher I trusted. He not only offered a mature perspective, but also had access to inside information. The team liked me, he reported, but my interests didn’t overlap with theirs enough. In a sense, I’d grown too independent. As independence marks maturity in PhD students, the rejection came to double as a compliment. Today, I remain on friendly terms with multiple people from that team, and a student of mine just landed an internship at a quantum-computing company.
Someone more experienced than you should have your back. (For the story behind this photo, see this blog post.)
Chart a path past the failure or rejection. Cue the lemon meringue pie. Did a hiring committee reject an application of yours? Email the committee’s chair, thanking them for considering your application. Express your hope of improving your materials so that you can try again the following year. Ask if the chair would provide feedback via phone or Zoom.1
Pursue the path you’ve charted. To ease the burden, consider undertaking lighter tasks before more-arduous ones. I recently received a laundry list of requests about a manuscript from an editor—and when I say laundry, I mean the equivalent of hauling a multiple-pound bag to a stream, scrubbing everything by hand while the wind attempts to blow cleaned items into the mud, and then hauling everything back. I began with the tasks that required little effort. Dispatching them, I crossed about half the requests off my to-do list. The list looked more manageable as a result; I felt better-equipped to handle the trickiest work.
Celebrate your triumphs. Don’t let failures and rejections consume your attention; carve out time for your successes. If you recognize them, you’ll remember them the next time you face failure; they’ll cushion you when you fall.
I recently failed at a task over a hundred times (yes, I counted). After 28 months of trying, I succeeded. I celebrated by treating myself to lunch at the National Gallery of Art.2 Why not gather ye rosebuds while ye may? This success afforded me the opportunity to fail at a new task.
The National Gallery of Art sold a fairly steampunk book near its Garden Café recently.
Always remember, what matters in the long run is not any one failure or rejection, but your persistence despite failures and rejections. I progressed to the Rhodes Scholarship competition’s final round two years in a row. Each year, a committee interviewed and rejected me. I’d poured time, sweat, and blood into my applications and interview preparations. I felt like I had no more blood to squeeze into the applications I then had to write for graduate programs because of those rejections. Those rejections, though, led me to become a student of John Preskill’s. Over a decade later, I’m not kicking myself.
Result of two failures.
Share about your favorite failures in the comments section below!
1Not via email, which doesn’t offer the same freedom.
2Its Garden Café had enticed me for years, but I can rarely bring myself to pay for food when I can prepare it myself.
When I was pursuing a PhD at Caltech, so was my friend Jeremy. He used to throw a dinner party every few months. The email invitations welcomed friends to partake of his cooking and, if we wished, to help him cook. I didn’t help cook; but, when I arrived, the mess of pots and pans drew me to the kitchen like vinegar drawing a pathological fly. I couldn’t sit still while cookware needed cleaning, so I scrubbed and rinsed the pans and spoons and bowls. Jeremy, an applied-physics student, commented on my adeptness at decreasing entropy.
It’s the story of my life, I replied.
In fourth grade, my classmates and I cleaned our desks every Friday afternoon. Once a student finished, my teacher dismissed him or her onto the playground. My neighbor’s desk horrified me like the disaster in a hurricane’s wake, so I neatened his desk after finishing with mine.1 Another friend requested the same favor. A third classmate offered to pay me for cleaning his desk, but I’d have undertaken the chore for its own sake. Ordering the world offered me fulfillment.
From cleaning a fourth-grade desk, I progressed to pursuing a PhD in theoretical physics. The two pursuits might seem to resemble each other no more than Dr. Jekyll and Mr. Hyde; yet, to me, the path between them is but a step. I trained as a theoretical physicist because I love organizing ideas. Caltech paid me to build models, propose definitions and theorems, and structure proofs—to dream up ideas and identify the optimal arrangements for them. I needed that pay, being an adult, as I hadn’t needed my fourth-grade classmate’s desk-cleaning fee. Yet I organized ideas for the same reason that drove me to organize my neighbor’s notebooks.
Many people have called entropy a measure of disorder. To see why, imagine that Jeremy’s crew has used thirty utensils while cooking. The chefs can have scattered the utensils across the kitchen in many ways: they may have dropped forks on the floor, left spoons in the sink, arranged spatulas on the drying rack, or filled a vase with knives like a modern-art bouquet. In few of these configurations do the forks lie in their compartment of the utensil drawer, the spoons lie in their compartment, etc. We call such configurations neat. Most of the other configurations, we call messy.
A system’s entropy is the number of configurations consistent with known large-scale properties of the system, such as the number of forks.2 More configurations are consistent with messiness (and a fixed number of forks and so on) than with neatness (and the same number of forks and so on). Messiness tends to correlate with high entropy. People often say, therefore, that entropy quantifies messiness. Hence Jeremy’s complimenting me on my decreasing of entropy.
Jeremy’s dinner parties came to mind as I read the book The Mattering Instinct, published by Rebecca Newberger Goldstein this January. Rebecca is a philosopher of science and a writer. I had the good fortune to meet her through my undergraduate mentor Marcelo Gleiser, who’s had another cameo or two on Quantum Frontiers. Rebecca’s latest book covers what she calls the mattering instinct: the longing to know that we matter.
We spend scads of energy and time on securing our “survival and flourishing,” as Rebecca says. We feed ourselves; work to earn money to purchase food; clean, shelter, and clothe ourselves; ingrain ourselves in societies that offer some degree of security; and more. Do we deserve all this effort? We long for assurance that, in the immortal words of L’Oreal, we’re worth it.
Survival and flourishing, Rebecca writes, requires us to decrease entropy. Every closed, isolated system’s entropy increases or remains constant, according to the second law of thermodynamics. Entropy increases as a system becomes more uniform, loosely speaking. The system’s particles spread out across space, these particles’ temperature comes to equal those particles’ temperature, and so on. In contrast, your body exists because its particles clump together in a certain shape consistently. You withstand heat waves and snow because homeostasis maintains your temperature despite your environment’s temperature. You keep your body’s entropy low to survive. Rebecca therefore casts us as fighting entropy.
As a thermodynamicist, I agree with Rebecca. Yet I also adore entropy. It helps explain why time flows, quantifies uncertainty, and determines the maximal efficiencies with which we can perform tasks such as communication. What versatility and richness! Entropy also embodies tension and subtlety: its mathematical definition looks obscure at first glance, yet entropy helps explain familiar phenomena such as aging. For these reasons, before beginning my PhD, I told a potential advisor that I could imagine devoting the next five years of my life to entropy.
I therefore aspire to rehabilitate entropy’s reputation. Novelist Terry Pratchett endeared mortality to millions of readers through anthropomorphism. His character Death, a mainstay of the Discworld series of novels, elicits empathy and fondness. I won’t anthropomorphize entropy here,3 but I aim to replace conflict with cooperation in the narrative above. To survive and flourish, I hold, we partner with entropy. How? We create oodles of entropy in our environments. This entropy increase offsets the entropy decrease that supports life.
For example, imagine working at a desalination plant. You’d process high-entropy water throughout which salt has spread. You’d concentrate the salt in a tiny region, reducing the water’s entropy. This reduction, producing fresh water, could support your city’s drinking, cooking, and toothbrushing needs.
To reduce the water’s entropy, you’d create loads more entropy. You’d eat breakfast before work, consuming energy stored neatly in your waffle’s chemical bonds. Your body would later break the bonds, releasing the energy. Some energy would power your muscles, so you could program the desalination system, test its output, etc. But much of the chemical energy would transform into heat radiated by your body. The heat would warm up the air molecules around you, magnifying their random jigglings and jostlings. You’d increase the entropy of the air—your environment—to decrease the water’s entropy. The air’s entropy increase would outweigh the water’s entropy decrease.
Organisms survive and flourish by producing entropy in their environments. In fact, organisms have a knack for generating entropy. Entropy and life thereby further each other. A glass-half-full thinker could conclude that we partner with entropy.
So did I partner with entropy as a PhD student, applying it to solve problems in quantum information theory and thermodynamics. So did I partner with entropy in fourth grade and at Jeremy’s apartment, deriving satisfaction from my cleaning. Rebecca would call these activities’ ultimate aim (beyond the aim of, e.g., not sitting beside a pigsty in fourth grade) mattering. She writes that we reduce entropy (within our immediate vicinities) to satisfy the mattering instinct. Rebecca’s proposition describes my behaviors with uncanny precision, I realized upon reading her book.
Which I’ve now finished. So pardon me while I return to washing forks in the quantum kitchen of the universe.
With thanks to Jeremy for his friendship…and food.
1I also ensured that my neighbor brought home, every afternoon, the sweater he’d brought to school that morning. Before I took charge, he’d ended up with three forgotten sweaters crammed into his cubby.
As experimental capabilities advance rapidly, the quantum computing community faces a critical elephant in the room: What will these quantum machines eventually be useful for? Will they deliver the promised broad societal impact, or will they remain highly specialized devices for exotic tasks known only to the experts?
The elephant in the room
Despite decades of effort, conclusive evidence of large quantum advantage in real-world applications remains confined to a few niche domains, such as simulating quantum materials and cryptanalysis. These problems are either inherently quantum to begin with, or they possess specialized mathematical structure that quantum algorithms can easily exploit. But it seems unlikely that such structures appear broadly in everyday life.
Indeed, most applications of modern computation hinge on the processing of massive, noisy classical data, generated at an unprecedented pace across society. That is the driving force behind the overwhelming success of machine learning and AI. Since the data originates from the macroscopic classical world, there is no obvious reason it should exhibit the delicate, specialized structures that quantum computers require. To playfully adapt Richard Feynman’s famous quote: We live in an effectively classical world, dammit, and maybe classical computers and AI already suffice for most of our problems. (For those unfamiliar, Feynman originally quipped: “Nature isn’t classical, dammit, and if you want to make a simulation of nature, you’d better make it quantum mechanical.”)
The central challenge
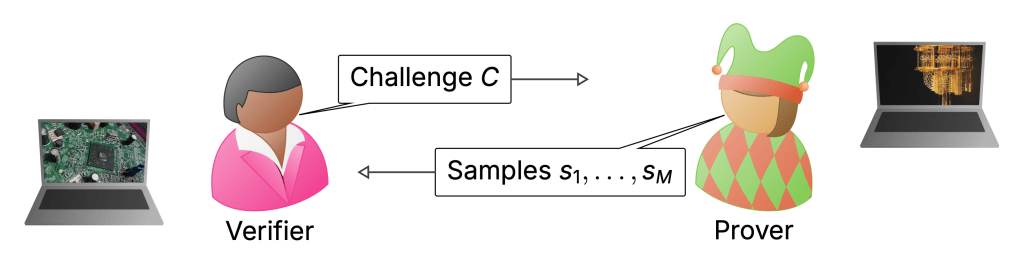
To truly unlock the power of a quantum computer, quantum algorithms typically need to access data in quantum superposition, processing many different samples simultaneously in different branches of the quantum multiverse. To use technical jargon, this is called querying a quantum oracle. But in reality, the classical data samples that we want to process are generated from everyday activities in a classical world, and we can only access them one at a time.
Think of the movie reviews you scroll through on a streaming platform. How would you read the plain-text reviews from a million different users all at once in a quantum superposition? This bottleneck—the challenge of efficiently accessing the classical world in quantum superposition—is known as the data loading problem. It has arguably been one of the main obstacles to achieving broadly applicable quantum advantage.
Sketching a quantum oracle
In this new work [1], we provide a solution to this seemingly impossible challenge. We develop a framework, called quantum oracle sketching, that enables us to access the classical world in quantum superposition in an optimal way. Importantly, it automatically handles the noise and correlations in the data, and natively supports flexible data structures like vectors and matrices that enable machine learning applications.
The core mechanism relies on processing data as a continuous stream. For each classical data sample we observe, we apply a carefully designed, small quantum rotation to our system. By sequentially accumulating these quantum rotations, we incrementally build up an accurate approximation of the target quantum oracle, which can then be used in any quantum algorithm for data processing. Because every data sample is processed once and immediately discarded, we completely eliminate the massive memory overhead typically required to store the dataset. The fundamental price to pay for assembling quantum queries from classical data lies in the sample complexity: our algorithm consumes a number of samples that scales quadratically with the number of quantum queries we need to make. We show that this rate is optimal and fundamentally arises from the quadratic relationship between quantum amplitudes and classical probabilities governed by the Born rule.
With the data successfully loaded into the quantum computer, the final challenge is to efficiently read out classical results. To address this, we develop an efficient measurement protocol called interferometric classical shadow. Combined with quantum oracle sketching, it allows us to circumvent the data loading and readout bottleneck to construct exponentially compact classical models from massive classical data with quantum technology.
Exponential quantum advantage in machine learning
Using this new approach, we are finally able to find exponential quantum advantage in processing classical data and machine learning. We rigorously prove that a small quantum computer can perform large-scale classification and dimensionality reduction on massive classical data by processing samples on the fly. In contrast, any classical machine achieving the same prediction performance requires exponentially larger size. When the classical machine does not have the required exponentially large memory size, it needs super-polynomially more samples and time relative to our protocol running on a quantum device. Remarkably, this illustrates that quantum technology enables us to construct compact and accurate classical models out of classical data, which is impossible with classical machines alone unless given exponentially larger memory.
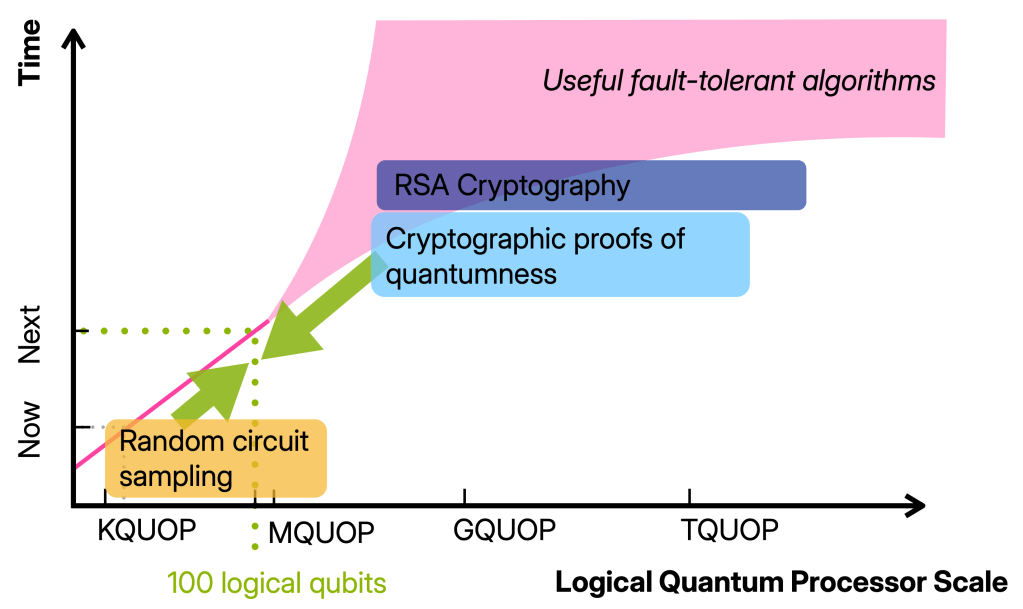
The true scale of this exponential memory advantage is staggering. A quantum processor with 300 logical qubits can outperform a classical machine built from every atom in the observable universe. Of course, to actually see such a comical contrast, we would also need universe-scale datasets and processing time.
To contextualize these results in realistic scenarios, consider a large-scale scientific experiment, like a large particle collider. Each experimental run generates a colossal volume of data. With a quantum computer, we can keep squeezing all the data into this tiny quantum chip to perform downstream machine learning tasks such as classification and dimensionality reduction. But if we only have classical machines, we would need to build massive, energy-consuming data centers to store the raw data to match the performance. Without this massive memory overhead, classical machines simply couldn’t extract the same clear signals from a single run, forcing us to repeat the massive, expensive experiment many more times to compensate. To put this into perspective, the Large Hadron Collider (LHC) at CERN generates petabytes (millions of gigabytes) of data per hour, but the data storage bottlenecks force researchers to discard all but a tiny fraction—retaining perhaps only one in a hundred thousand events.
We validated these quantum advantages on real-world datasets, including movie review sentiment analysis and single-cell RNA sequencing. In these public datasets, we demonstrate four to six orders of magnitude (ten thousand to a million times) reduction in memory size with fewer than 60 logical qubits. Given the rapid advancements in high-rate quantum error correction codes and experimental techniques, quantum computers capable of demonstrating such applications are foreseeable in the near future. Crucially, the quantum advantage we propose likely carries a clearer positive impact for society and likely arrives sooner than the applications in cryptanalysis, where the current best estimate requires a thousand logical qubits.
Towards Quantum AI
Our results provide strong evidence that the utility of quantum computers extends far beyond specialized tasks, opening a path for quantum computers to be broadly useful in our everyday life. Rather than fearing that classical AI will “eat quantum computing’s lunch,” we now have rigorous evidence pointing towards a much more exciting prospect: quantum-enhanced AI overpowering classical AI.
Of course, there is still a long way to go towards the dream of quantum intelligence. Our current results establish the provable supremacy of quantum machines in foundational machine learning tasks, such as high-dimensional linear classification and dimensionality reduction. They do not yet imply immediate utility for modern generative AI such as large language models.
That said, our results give me a strong feeling that we are living in an age strikingly reminiscent of the traditional machine learning era—an age dominated by support vector machines and random forests; an age when we relied on rigorous statistical analysis because we lacked the computational resources for large-scale heuristic exploration; an age that ultimately heralded the birth of deep learning and the AI revolution. Today, quantum AI seems to sit at a similar historical position. I cannot wait to see what quantum AI will become once we are capable of unconstrained heuristic exploration on large-scale fault-tolerant quantum computers.
To accelerate this dawn of quantum AI, we invite physicists, computer scientists, developers, and machine learning practitioners to join our efforts and help us push the boundaries of what quantum AI can achieve. To bridge the gap between abstract quantum theory and hands-on machine learning practice, we are open-sourcing our core framework. Our numerical implementation of quantum oracle sketching is built in JAX, natively supporting GPU/TPU acceleration and automatic differentiation to integrate nicely with modern machine learning pipelines. Check out the code, run the simulations, and help us shape the future of quantum AI at github.com/haimengzhao/quantum-oracle-sketching!
Recently, my coworkers and I put out a preprint “Classical solution
of the FeMo-cofactor model to chemical accuracy and its
implications’’ (Zhai et al. 2026). It is a bit
unusual to write commentary on one’s own scientific article. However, in
this case, given the many inquiries I have had about the work in the
context of quantum computing, many of which have contained similar
questions (and often similar misunderstandings), I thought it would be
useful to provide some perspective that we could not provide in the
original preprint, in an informal manner.
What is FeMo-co?
I will start with some background on the FeMo-cofactor (FeMo-co).
This cofactor is the reaction center of nitrogenase, an enzyme found in
certain soil-dwelling bacteria. Nitrogenase’s claim to fame is that it
converts atmospheric dinitrogen, which is held together by a strong N-N
triple bond, into a reduced form (ammonia) which can then be taken up by
plants and thereby be passed onto the rest of the living biomass. In
terms of incorporating nitrogen into biomass, nitrogenase is believed to
be responsible for about 2/3 of
biological nitrogen, with the remainder coming from fertilizers. Because
it plays this critical role, it is sometimes referred to as the enzyme
that feeds the planet.
The chemistry of how dinitrogen is reduced at the FeMo-cofactor is still largely unknown. The basic stoichiometry of the reaction is often written as
but this just a sketch of the process. In particular, the above equation contains, nominally, a large number of molecular reactants, and clearly they do not all just come together in a bang! The role of the cofactor, and the enzyme more generally, is to coordinate the protons, electrons, biological energy source (ATP), and the dinitrogen molecule, into a sequence of well-defined steps, known as the reaction mechanism. Since the work of Lowe and Thorneley (Thorneley and Lowe 1984), the most common proposal for the nitrogenase reaction mechanism contains 8 intermediate steps (corresponding roughly to 8 sequential proton and electron additions). However, due to the difficulty in isolating the intermediate states of FeMo-co, as well as challenges in using experimental probes to deduce what these states are, the Lowe-Thorneley cycle still remains an unproven hypothesis. Biochemists, spectroscopists, as well as a few theoretical quantum chemists, are today actively engaged in observing, computing, deducing (and arguing about) the nitrogenase mechanism (Jiang and Ryde 2023; Lancaster et al. 2011; Einsle and Rees 2020; Badding et al. 2023; Thorhallsson et al. 2019).
So how did nitrogenase become so widely discussed in the setting of
quantum computing? In 2016, an article “Elucidating reaction mechanisms
on quantum computers’’, that has since become one of the most cited
papers in the nitrogenase field, arguably started this all (Reiher et al.
2017). The article included a number of proposals, including (1)
that the ‘promise of exponential speedups for the electronic structure
problem’ could be applied to elucidate the nitrogenase reaction
mechanism that had so far proved intractable for classical computation,
and (2) that solving this problem would be an example of how quantum
simulation could be ‘scientifically and economically impactful’.
(Similar proposals can also be found repeated in less technical language
and settings, see e.g. ‘Why do
we want a quantum computer’). An important technical contribution of
the article was to provide a detailed quantum resource estimate for a
simulation of chemistry. The problem statement was to compute the
ground-state energy of a specific ‘54 orbital’ (108 qubit) model of
FeMo-co, to an accuracy of 1 kcal/mol, referred to as chemical accuracy.
It is important to note the word ‘model’ in the problem statement.
Electrons move in continuous space, and thus quantum chemical
Hamiltonians are formulated in the continuum, while quantum computation
requires discretization of this space. This discretization, in terms of
a so-called active space set of orbitals that the electrons can
variously occupy, constitutes the model. We will return to the
definition of the model below. By compiling a Trotter-Suzuki
implementation of the quantum phase estimation algorithm within a
fault-tolerant resource model for their specific FeMo-co model
Hamiltonian, Ref. (Reiher et al. 2017) provided
a T-gate resource estimate. Combined with some assumptions about the
quantum architecture, this provided perhaps the first concrete time-cost
to solve an interesting chemistry problem on a quantum computer. This
work has since served as an inspiration for many subsequent quantitative
resource estimation efforts in the quantum computing for chemistry
field.
Exponential speedup and
societal impact
Before proceeding further in this story, it is worth examining the
two key propositions made in Ref. (Reiher et al. 2017). I start
with the question of exponential speedup. Quantum algorithms for the
ground-state energy, such as quantum phase estimation, essentially
perform a projective measurement of the energy (encoded in a phase).
Thus, it is essential to prepare a good initial state, i.e. with large
overlap with the desired eigenstate, to measure the correct energy.
This, however, is a strong constraint, if we are seeking asymptotically
large quantum advantage. For example, if such an initial state is first
determined classically, as is often suggested, then exponential quantum
advantage in a given problem requires that finding good classical
guesses is easy, while improving them classically to fully solve the
problem becomes exponentially hard as the problem size increases.
Unfortunately, convincing evidence that chemically relevant electronic
structure problems, including the problem of cofactor electronic
structure exemplified by FeMo-co, fall into this category has not yet
been found, as discussed in detail in Refs. (Lee et al. 2023; Chan
2024).
The second proposition, that elucidating the reaction mechanism of
nitrogenase will lead to a transformative societal impact, is similarly
nuanced. The claim originates in the observation that the competing
industrial process for fertilizer production via nitrogen reduction,
namely, the Haber-Bosch process, takes place at high temperatures and
pressures and consumes a significant percentage of the world’s energy.
Bacteria, on the other hand, can do this process at room
temperature.
While it is true that the nitrogenase enzyme functions at ambient
temperature and pressure, it is simply false that it consumes much less
energy. This is because the large amount of energy required for nitrogen
fixation mainly originates from thermodynamics, i.e. one needs energy to
break the strong nitrogen triple bond. In fact, taking into account the
physiological conditions and the ATP cost, bacteria arguably expend
more energy to reduce ammonia (Chan 2024) than a modern efficient
industrial implementation of the Haber-Bosch process. Thus the real hope
behind trying to understand the nitrogenase mechanism in the context of
societal impact is that we may one day engineer a variant of it with
more desirable properties, e.g. with higher turnover, or with a lower
carbon footprint, or which is more selective for nitrogen reduction.
Whether this is actually possible remains to be seen, and certainly
requires much more than knowing the ground-state of FeMo-co, or even the
full reaction mechanism.
Which FeMo-cofactor model?
I now return to the question of FeMo-cofactor models. Ref. (Reiher et al.
2017) introduced a particular cofactor model, which I will refer
to it as RWST, following the names of the authors. As we soon found out,
simulating the ground-state of the RWST model was actually very easy
classically, and in fact (as reported in (Li et al. 2019)) could be done
using standard quantum chemistry methods with a few hours of calculation
on a laptop. This was because although the RWST model was a 108 qubit
model, and (in the worst case) a 108 qubit ground-state cannot be stored
classically, the RSWT model Hamiltonian was constructed in such a way to
not capture any of the difficult features of the FeMo-cofactor
ground-state. This highlights the importance of not assuming worst case
complexity about physical problems!
What makes the electronic structure of the FeMo-cofactor (relatively)
complicated is the presence of many ‘unpaired’ electrons. In simple
molecules, we can describe the ground-state as one where all the
electrons sit in pairs in orbitals. Since an orbital can only carry a
pair of electrons at a time, the ground-state is simply described by
filling the lowest energy orbitals with pairs. However, in molecules
with transition metals, there are typically ‘unpaired’ electrons
(so-called open-shells), and then we need to consider whether and how
they pair up, which orbitals are singly versus doubly occupied, and so
on. The RSWT model ground-state had no unpaired electrons! It was
therefore unrepresentatively easy to solve for the ground state
classically.
Because of the problems with the RWST model, my group formulated a
more suitable 76 orbital/152 qubit model of FeMo-co in Ref. (Li et al. 2019),
which I will refer to as the LLDUC model, again by the names of the
authors. Although the LLDUC model is still a significant truncation of
the true electronic structure of FeMo-co, we verified that it contains
the correct open-shell character of the cofactor, and thus has a
‘representative’ complexity in its ground-state. Since we published the
LLDUC model, it has become the most common benchmark model of FeMo-co
used in quantum resource estimates for new quantum chemistry
ground-state algorithms (Wan
et al. 2022; Berry et al. 2019; Luo and Cirac 2025; Low et al.
2025).
Heuristics
in the classical solution of the LLDUC FeMo-cofactor model
This brings me now to the recent work in Ref. (Zhai et al. 2026), where, through
a sequence of classical calculations, we could produce a classical
estimate of the ground-state energy of the LLDUC model to chemical
accuracy. How was this achieved?
Classical electronic structure methods (aside from exact
diagonalization) are heuristic algorithms. Much like quantum algorithms,
they implicitly or explicitly start from an initial state. In chemical
applications, this can be viewed as a product state or set of product
states: for tensor network algorithms, such as the density matrix
renormalization group (when not considering topological order) this is
the set of states (specified by
the underlying basis) which connect to the space of slightly entangled
states with that the
algorithm naturally explores. In coupled cluster methods, this is the
initial reference state to which excitations are applied. Although many
classical heuristics are exact with exponential effort, e.g. by
increasing the bond dimension in
a tensor network or excitation level in coupled cluster theory, in
practical computational chemistry, classical heuristics are used with
the assumption that so long as the initial state is chosen
appropriately, they will converge rapidly to the true ground-state
without exponential effort. I analyze this heuristic working assumption
in Ref. (Chan
2024) where I name it the classical heuristic cost conjecture.
However, finding the good classical initial state is an NP hard problem,
and this is often the crux of where the challenge in simulation actually
lies.
In FeMo-co, unlike in simpler molecules, it is not at all obvious
what product state to start from. To address this, in Ref. (Zhai et al.
2026), we devised an enumeration and filtering protocol. The
relevant manifold arises from the orbital and spin degrees of freedom of
the Fe ions: which Fe orbitals are occupied, by how many electrons, and
with which spins. One technical point is that the resulting product
states do not generally conserve the global spin symmetry. However, as recognized
by Anderson decades ago, for magnetic order in large systems, the
eigenstates can be chosen to break symmetry due to the tower of symmetry
preserving eigenstates at an energy scale of (where is the system volume). For a finite
energy resolution we can equally use a broken symmetry description
of the states, an example of the fragility of entanglement effects in
physical systems.
Because applying the highest level of classical approximation to all
enumerated product states was far too expensive, we used a filtering
funnel, where product states were ranked at different levels of theory,
passing promising candidates to higher levels of classical computation.
In the end, the final most accurate calculations were performed on only
3 candidates, which we deduced to all be essentially degenerate to
within chemical accuracy.
There are other important technical details in Ref. (Zhai et al.
2026) which I have not mentioned: the use of unrestricted
orbitals, the systematic extrapolations to obtain the final energies and
estimated errors, and the benchmarking required to be confident about
the protocol. However, recognizing that the FeMo-co ground-state problem
could be reduced essentially to a ranking problem was the essence of
what made the estimate possible.
Implications
of the classical solution for chemistry
From a chemical and biochemical perspective, computing the
ground-state energy of a model to some specified accuracy – even
chemical accuracy – is a highly artificial target. Most chemical
calculations that have an impact on our understanding never achieve or
even target chemical accuracy in the total energy. In addition,
chemistry does not depend on the the total energy, but the relative
energy of different chemical configurations, which typically differ only
by changes in the bonding and
chemistry.
The main take-home from our work then is that there is nothing
especially mysterious about FeMo-co’s electronic structure. The story of
the FeMo-co ground-state is not one of multiconfigurational electronic
structure (i.e. where the states are not at all close to product
states), but one of multiple configurations (i.e. many competing product
states). Indeed, this is basically how nitrogenase chemists have long
reasoned about the electronic structure of iron-sulfur clusters and
FeMo-co (Lovell et al. 2001;
Yamaguchi et al. 1990). Our work thus now provides extensive and
rigorous numerical support for this picture.
Because of this simplicity, the full richness of classical quantum
chemistry methods can now be brought to bear on FeMo-co electronic
structure beyond the LLDUC model. Assuming the model already captures
the qualitative complexity of the cluster’s electronic structure, we
expect such investigations to provide quantitative corrections to the
picture we have obtained. We took some initial steps to confirm this in
our manuscript, considering larger orbital spaces, the effect of protein
fluctuations, and the interpretation of certain spectroscopies. In the
future, connecting these simulations to more spectroscopic measurements
will be an exciting possibility. In addition, now that the electronic
structure is on a conceptually sound footing, we have a foundation to
support the central question of resolving the reaction mechanism. This
opens up a whole new set of scientific challenges associated with
observing reactions on extremely slow timescales.
Implications
of the classical solution for quantum computing in chemistry
Because of the success of classical heuristic methods for this
problem, one may naturally wonder what these results mean for the
application of quantum computers in chemistry. Here I address some
commonly asked questions.
Is the classical simulation of the LLDUC model a ‘last hurrah’ for classical methods?
I have seen the analogy drawn between the FeMo-co result and the classical tensor network simulations for random circuit sampling experiments. In that case, while the famous Google Sycamore experiment (Arute et al. 2019) could be replicated by classical tensor network simulations (Gray and Kourtis 2021), subsequent improvements in quantum processors, soon led to random circuit sampling experiments outpacing the capabilities of classical simulations.
However, the situation here is quite different. There is strong
evidence that generating samples from a random quantum circuit (without
noise) is actually exponentially hard to do using a classical algorithm,
and indeed, the classical simulations used for the task were (mostly)
brute force simulations with exponential cost in circuit size. In
contrast, the theoretical support for exponential quantum advantage in
the FeMo-co problem is much weaker, and as an empirical fact, most of
the methods used in the FeMo-co simulation (namely the coupled cluster
methods for a given excitation level) are polynomial cost algorithms.
Since a similar simulation strategy has also been successfully applied
across the series of 2, 4, and 8 metal iron-sulfur complexes (Sharma
et al. 2014; Li et al. 2019; Zhai et al. 2023, 2026), we have no
reason to expect a radically different situation if we consider larger
analogous complexes in this series.
And in any case, chemistry does not provide an endless scaling of problem size; FeMo-co is the largest enzyme cofactor in terms of the number of transition metals. Materials simulations provide a setting to scale the problem size, but one still faces the question as to whether the relevant states observed are truly that complicated classically. For example, classical simulations of the ground-state orders of the 2D Hubbard model currently show no exponential increase in difficulty when going to larger system sizes (Chen et al. 2025; Liu et al. 2025).
Has the availability of a classical strategy for FeMo-co changed your enthusiasm for quantum computers in chemistry?
Again, my answer is no. There is an entire community of nitrogenase scientists: experimental spectroscopists, synthetic chemists, and of course computational chemists, who are working to map out the reaction mechanism, none of whose research is predicated on using a quantum computer. Personally, I have never thought that to understand nitrogenase we would first have to build a quantum computer, otherwise I would not work on the problem!
At the same time, any computational tool brings new capabilities that
will be useful. Quantum algorithms come with theoretical guarantees; for
example, so long as the initial state is well prepared, we know the
error in the energy that we measure from a quantum algorithm, which is
more reliable than the classical estimates of error we obtain from
extrapolations. Similarly, initial state preparation for a quantum
computer, even for classically tractable problems, is probably easier
than solving the entire problem classically, since only a ‘rough’ guess
is needed. And finally, a polynomial or even constant factor speedup is
exciting, so long as the speedup is large enough!
Thus, I am in fact excited to see quantum computers applied to this
problem, I am just not waiting for them to be built first.
How should one think about past work on quantum algorithms that has used FeMo-co as a target?
FeMo-co was amongst the earliest examples of a chemical problem for which a case for quantum advantage was made. For this reason, it is overrepresented in the literature of quantum computing for chemistry. Should fully fault-tolerant quantum computers be available, they will naturally be applied to a wider set of systems (Chan 2024; Babbush et al. 2025).
Also, one must recognize that the availability of a single concrete optimization target has led to undeniable advances in quantum algorithms for quantum chemistry. In most cases, prior work to improve quantum resources estimates for FeMo-co involve techniques that apply to other systems as well. Thus, there’s no need to throw away those papers!
What are some lessons and conclusions to draw?
The first is obviously that, just because something has not been solved, or appears hard to solve classically, does not mean it is the best problem to choose for a quantum computer. The classical solution strategy for FeMo-co essentially involved a complicated classical state preparation problem, which is a shared challenge with ground-state estimation algorithms in quantum computers, and thus not perhaps an optimal choice of problem.
My second main conclusion is that since classical solutions in
complex problems are possible because they use some understanding of the
problem, for quantum algorithms to have maximum impact, they should use
the same knowledge. In fact most chemistry is not about truly mysterious
quantum systems, but more about ordinary quantum matter where we know
roughly what is going on, but where detailed simulations are still
required. If quantum computing algorithms can target this ‘mundane’
regime, they will have maximum impact on chemistry as it is practiced
today. In recent work, we have taken some steps in this direction by
proposing quantum algorithms for electronic structure that work within
the same heuristic framework as most current quantum chemistry
methods (Chen and
Chan 2025).
Finally, I wish to emphasize that, from the perspective of
understanding nitrogenase, and maximising societal impact, the choice of
computational algorithm and hardware to solve the problem is irrelevant.
The fact that FeMo-co electronic structure is not so mysterious is an
enormously positive thing, as it means that making progress on the
larger problem of the mechanism using computation no longer seems so
impossible. I have seen some of the brightest minds in the world helping
to advance quantum algorithms for this problem. If any of this
brainpower can be devoted to the chemical question itself, I believe we
can be very optimistic about the future solution of the nitrogenase
problem.
References
Arute, Frank, Kunal Arya, Ryan Babbush, et
al. 2019. “Quantum Supremacy Using a Programmable
Superconducting Processor.”Nature 574 (7779): 505–10.
Babbush, Ryan, Robbie King, Sergio Boixo, et al. 2025. “The Grand
Challenge of Quantum Applications.”arXiv Preprint
arXiv:2511.09124.
Badding, Edward D, Suppachai Srisantitham, Dmitriy A Lukoyanov, Brian M
Hoffman, and Daniel LM Suess. 2023. “Connecting the Geometric and
Electronic Structures of the Nitrogenase Iron–Molybdenum Cofactor
Through Site-Selective 57Fe Labelling.”Nature Chemistry 15 (5): 658–65.
Berry, Dominic W, Craig Gidney, Mario Motta, Jarrod R McClean, and Ryan
Babbush. 2019. “Qubitization of Arbitrary Basis Quantum Chemistry
Leveraging Sparsity and Low Rank Factorization.”Quantum
3: 208.
Chan, Garnet Kin-Lic. 2024. “Spiers Memorial Lecture: Quantum
Chemistry, Classical Heuristics, and Quantum Advantage.”Faraday Discussions 254: 11–52.
Chen, Ao, Zhou-Quan Wan, Anirvan Sengupta, Antoine Georges, and
Christopher Roth. 2025. “Neural Network-Augmented Pfaffian
Wave-Functions for Scalable Simulations of Interacting Fermions.”arXiv Preprint arXiv:2507.10705.
Chen, Jielun, and Garnet Kin Chan. 2025. “A Framework for Robust
Quantum Speedups in Practical Correlated Electronic Structure and
Dynamics.”arXiv Preprint arXiv:2508.15765.
Einsle, Oliver, and Douglas C Rees. 2020. “Structural Enzymology
of Nitrogenase Enzymes.”Chemical Reviews 120 (12):
4969–5004.
Jiang, Hao, and Ulf Ryde. 2023. “N2 Binding to the E0–E4 States
of Nitrogenase.”Dalton Transactions 52 (26): 9104–20.
Lancaster, Kyle M, Michael Roemelt, Patrick Ettenhuber, et al. 2011.
“X-Ray Emission Spectroscopy Evidences a Central Carbon in the
Nitrogenase Iron-Molybdenum Cofactor.”Science 334
(6058): 974–77.
Lee, Seunghoon, Joonho Lee, Huanchen Zhai, et al. 2023.
“Evaluating the Evidence for Exponential Quantum Advantage in
Ground-State Quantum Chemistry.”Nature Communications
14 (1): 1952.
Li, Zhendong, Sheng Guo, Qiming Sun, and Garnet Kin-Lic Chan. 2019.
“Electronic Landscape of the P-Cluster of Nitrogenase as Revealed
Through Many-Electron Quantum Wavefunction Simulations.”Nature Chemistry 11 (11): 1026–33.
Liu, Wen-Yuan, Huanchen Zhai, Ruojing Peng, Zheng-Cheng Gu, and Garnet
Kin-Lic Chan. 2025. “Accurate Simulation of the Hubbard Model with
Finite Fermionic Projected Entangled Pair States.”Physical
Review Letters 134 (25): 256502.
Lovell, Timothy, Jian Li, Tiqing Liu, David A Case, and Louis Noodleman.
2001. FeMo Cofactor of
Nitrogenase: A Density Functional Study of States MN, MOX, MR, and
MI.” Journal of the American Chemical Society 123 (49):
12392–410.
Low, Guang Hao, Robbie King, Dominic W Berry, et al. 2025. “Fast
Quantum Simulation of Electronic Structure by Spectrum
Amplification.”arXiv Preprint arXiv:2502.15882.
Luo, Maxine, and J Ignacio Cirac. 2025. “Efficient Simulation of
Quantum Chemistry Problems in an Enlarged Basis Set.”PRX
Quantum 6 (1): 010355.
Reiher, Markus, Nathan Wiebe, Krysta M Svore, Dave Wecker, and Matthias
Troyer. 2017. “Elucidating Reaction Mechanisms on Quantum
Computers.”Proceedings of the National Academy of
Sciences 114 (29): 7555–60.
Sharma, Sandeep, Kantharuban Sivalingam, Frank Neese, and Garnet Kin-Lic
Chan. 2014. “Low-Energy Spectrum of Iron–Sulfur Clusters Directly
from Many-Particle Quantum Mechanics.”Nature Chemistry
6 (10): 927–33.
Thorhallsson, Albert Th, Bardi Benediktsson, and Ragnar Bjornsson. 2019.
“A Model for Dinitrogen Binding in the E4 State of
Nitrogenase.”Chemical Science 10 (48): 11110–24.
Thorneley, Roger NF, and DJ Lowe. 1984. “The Mechanism of
Klebsiella Pneumoniae Nitrogenase Action. Pre-Steady-State Kinetics of
an Enzyme-Bound Intermediate in N2 Reduction and of NH3
Formation.”Biochemical Journal 224 (3): 887–94.
Wan, Kianna, Mario Berta, and Earl T Campbell. 2022. “Randomized
Quantum Algorithm for Statistical Phase Estimation.”Physical
Review Letters 129 (3): 030503.
Yamaguchi, Kizashi, Takayuki Fueno, Masa-aki Ozaki, Norikazu Ueyama, and
Akira Nakamura. 1990. “A General Spin-Orbital (GSO) Description of
Antiferromagnetic Spin Couplings Between Four Irons in Iron-Sulfur
Clusters.”Chemical Physics Letters 168 (1): 56–62.
Zhai, Huanchen, Seunghoon Lee, Zhi-Hao Cui, Lili Cao, Ulf Ryde, and
Garnet Kin-Lic Chan. 2023. “Multireference Protonation Energetics
of a Dimeric Model of Nitrogenase Iron–Sulfur Clusters.”The
Journal of Physical Chemistry A 127 (47): 9974–84.
Zhai, Huanchen, Chenghan Li, Xing Zhang, Zhendong Li, Seunghoon Lee, and
Garnet Kin-Lic Chan. 2026. “Classical Solution of the FeMo-Cofactor
Model to Chemical Accuracy and Its Implications.”arXiv
Preprint arXiv:2601.04621.
Your inbox registers an email from the chair of a faculty-hiring committee. With trembling fingers, you click on the message. “We were very impressed…we’re delighted to offer…” Months of labor, soul-searching, strain, and anxiety give way to jubilation. You hug your partner/roommate/mom/dog; throw an impromptu dance party; and forward the email, prefaced with five exclamation points, to your mentor.1
As your heart rate returns to a level less likely to alarm a cardiologist, a new source of uncertainty puckers your brow. You’ve received an offer of a faculty position. What happens now? How should you proceed?
This article will address those questions. It follows my guide to faculty interviews, which follows my guide to writing research statements. Like the former guide, this one pertains most to theoretical physicists seeking assistant professorships at R1-level North American universities. Yet all the advice pertains to candidates outside this pool.
The institution will bring you (and, if relevant, your partner) over for a visit. Yes, you visited to interview; but you’re now visiting for another purpose. Assess whether you and your family could flourish if you accepted the offer. Which neighborhoods might you like to live in? Could you tolerate the commute to campus? Vide infra for more questions to keep in mind.
Politely notify the other hiring committees that interviewed you and that are still considering your application. You’ll do the other committees a kindness: their chances of hiring you have narrowed. If they wish to lure you, they’ll need to act quickly. The notice may bump you up in their priority lists. Did the first institution request that you decide about its offer by some deadline? If so, notify the other institutions.
Gather all the information you need. The department may offer to put you in touch with faculty members, deans, and more. Request more connections if necessary. Approach each conversation with a list of questions, and take notes. How will the tenure process unfold? How do early-career faculty members characterize their experiences with it? To what extent does the department shield early-career faculty from administrative duties (serving on committees)? How do the institutions’ policies address parental leave and elder care? If you have a child as an assistant professor, will your tenure clock pause for a year (will you be able to build your credentials for an extra year before applying for tenure)? In which neighborhoods should you search for a house?
List your priorities. Rank them. Measure each offer against each criterion. Here are example priorities that you might wish to include:
Salary
Startup package
Type of environment: Do you want to live in a city, in the suburbs, or in the country? Do you drive, or would you learn to drive?
Length of commute
Geographical location: Do you prefer to live near family?
Proximity, and means of transportation, to an airport: You might commute to and from that airport many times to participate in conferences, present seminars, etc. How much time and exhaustion would the experience cost?
Local school system: If you have or might have children, where would they learn?
Partner’s needs: Do you have a partner who would need to find a job near yours?
Proximity of faculty with whom you could collaborate
Courtesy positions in other departments: Suppose you’re a physicist who studies quantum computation. You might want to recruit students from the computer-science or math department occasionally. Could you? Would you need a courtesy position in the other department? A courtesy appointment offers you limited privileges at the cost of limited responsibilities: you probably won’t be able to vote in the other department’s faculty meetings. On the other hand, you probably won’t need to spend time on those faculty meetings.
Academic quality of undergraduate/graduate population
Presence of an institute/center dedicated to your specialization
Lab space: location, size, quality, renovations available, how soon and quickly the university would undertake those renovations
Help with finding housing: Some universities have apartments that new faculty can rent for a year or two. Other universities offer real-estate-agent services or help faculty obtain mortgages (*cough* San Francisco Bay area *cough*).
Administrative assistance for you and your research group
Protection from onerous service to the department until you reach tenure
Teaching relief granted en route to tenure: At some universities, a new faculty member can avoid teaching their usual course load during one or two semesters. Such relief frees you to buff up your research program while pursuing tenure.
Deferral: Deferring an offer, you postpone the time at which you take up the new mantle. When I accepted a permanent position, I was completing year two of a three-year postdoctoral fellowship. I wanted to complete the final year before assuming my new role: I was still finishing projects with the community to which I belonged, and I wanted to continue deepening my ties with that community. Also, I enjoyed undertaking research without the distraction of a primary investigator’s administrative responsibilities. Other people defer their start dates for other reasons. For example, a partner might need time to fulfill a contract where they live and work. In my experience, people tend to defer PI positions for approximately twelve months, give or take six months. Some institutions don’t offer deferrals, though.
Identify everything you’ll need in a startup package. A startup package helps cover your research program’s costs until you’ve won your first grants. Multiple organizations within a university might contribute to a startup package—for example, a department and an institute that cuts across departments. The hiring committee might propose a startup package to you, or the committee might ask you what you need. Either way, you can (and should) negotiate the package.
View the negotiation in terms of the question “What do I need to succeed?” List every item, and estimate its cost. Don’t skimp on rigor: estimate prices to the single-dollar level of precision. Such precision helps demonstrate the thoroughness of the research behind your list—helps demonstrate that you need every dollar you seek.
Request more funding than you believe you’ll need, because you will need more than you believe. Build the breathing room into your estimates. For example, assume that your academic visitors will fly from across the country or across the world. Assume that you’ll fly such distances to present talks. Estimating how much you’ll pay a student or postdoc throughout the next few years? Don’t forget that the university might raise salaries and benefits under a cost-of-living adjustment (COLA) every year. COLAs fluctuate across years, so assume you’ll face steep ones.
Here are examples of items that a startup package can include:
Summer salary: Your institution won’t pay your salary during the summer; you’ll need to fund yourself through grants. A startup package can cover the initial summers.
Lab equipment
Computers and tablets for you and your group members: Don’t forget protective cases, AppleCare or a non-Apple equivalent, implements for writing on tablets, external mice, and external monitors. Check whether your department or institute has spare mice or monitors that you can requisition.
Other computational resources: Does the department have a computational cluster that you intend to use? Do you need to access a national lab’s supercomputer or a quantum computer available on the cloud? How much will you pay per unit time and memory?
Postdoc costs: These costs include a salary, benefits, and the cost of moving to your institution. The salary will increase from year to year if the institution implements a COLA. The benefits include healthcare, dental care, and the like. Administrators might call benefits “fringe,” as I discovered after considerable confusion.
Graduate-student costs: These costs include a research assistantship, benefits, and possibly tuition. The salary might increase as a student progresses through the stages of their PhD, particularly once they achieve candidacy. Their need for tuition might change, too. Check whether domestic students cost more than international students, and budget for international students.
Undergraduate researchers: Do you plan to employ an undergraduate during the summer? Throughout the academic year?2
Travel for yourself: Budget several trips per year for yourself. You’ll need to spread the word about your research and to grow your network en route to tenure.
Travel for your postdocs and students: A mentor shared that she covers one conference per year per group member. You might want to budget also for a seminar or two per group member per year.
Visitors: Visitors can boost your research program. Budget for week-long visits if your institution can accommodate them.
Negotiate. Even if your dream school has offered you your dream job. Even if you receive only one offer. You might still garner resources that can help your research program and family to thrive. Don’t feel shy, sheepish, or ashamed to negotiate. If you remain polite and considerate, you won’t offend anyone. Besides, the hiring committee, department chair, and dean expect you to negotiate. The department chair might even hope that you do so; vide infra.
When I was a PhD student, Caltech offered a workshop about negotiation to women grad students. The workshop helped participants build skills, knowledge, and self-assurance that would benefit us when we negotiated contracts. I recommend attending a workshop, taking a course, reading a book, or watching videos about negotiation. Contact your institution’s professional-development office about opportunities and suggestions. If you’re reading this blog post before applying for jobs—any jobs—start now.
What can you negotiate for? Many of the items on your list of priorities. Certain institutions might lack the freedom to negotiate certain items, though. For example, a union might determine salaries. Don’t let such a discovery discourage you; explore the options thoroughly.
View the department chair as an ally. The department chair negotiates on your behalf with administrators higher up in the university hierarchy, such as deans. The chair aims to garner as many resources as possible for you—and, by extension, for their department. Explain to the department chair (or to the committee chair who might explain to the department chair) what you need and why you need it, to help strengthen their argument.
As soon as you know you’ll decline an offer, decline it politely. Your notification will free the committee to attract another candidate. Imagine you’re Candidate #2 on the priority list. Wouldn’t you want the current offer recipient to decline their offer as soon as their conscience allows? Now, imagine you’re the hiring-committee chair. You’re worried that Candidate #1 will decline—and, by the time they decline, other institutions will have snapped up the other top candidates. As Candidate #1, demonstrate toward the committee chair and toward Candidate #2 the consideration that you’d value if in their shoes.
Savor the moment. You’ve just survived the faculty-application process, one of the most stressful periods of your life. The faculty life is no walk in the park, either. Nor will you necessarily sleep soundly between the receipt of your first offer and your signing of a contract. The prospect of more offers could leave you in limbo. If you receive multiple offers, choosing between them—choosing the course of your and your family’s life—may stress you as much as applying did. So remember to feel grateful for the source of your anxiety. Give yourself credit for your accomplishment.
Congratulations!
1Please do! They’ll want to celebrate with you.
2I recommend targeting undergrads who’ll work with you for more than a summer. Training an undergrad takes nearly a summer; you and the student will benefit from having time to take advantage of that training.
We are now at an exciting point in our process of developing quantum computers and understanding their computational power: It has been demonstrated that quantum computers can outperform classical ones (if you buy my argument from Parts 1 and 2 of this mini series). And it has been demonstrated that quantum fault-tolerance is possible for at least a few logical qubits. Together, these form the elementary building blocks of useful quantum computing.
And yet: the devices we have seen so far are still nowhere near being useful for any advantageous application in, say, condensed-matter physics or quantum chemistry, which is where the promise of quantum computers lies.
So what is next in quantum advantage?
This is what this third and last part of my mini-series on the question “Has quantum advantage been achieved?” is about.
The 100 logical qubits regime I want to have in mind the regime in which we have 100 well-functioning logical qubits, so 100 qubits on which we can run maybe 100 000 gates.
Building devices operating in this regime will require thousand(s) of physical qubits and is therefore well beyond the proof-of-principle quantum advantage and fault-tolerance experiments that have been done. At the same time, it is (so far) still one or more orders of magnitude away from any of the first applications such as simulating, say, the Fermi-Hubbard model or breaking cryptography. In other words, it is a qualitatively different regime from the early fault-tolerant computations we can do now. And yet, there is not a clear picture for what we can and should do with such devices.
The next milestone: classically verifiable quantum advantage
In this post, I want to argue that a key milestone we should aim for in the 100 logical qubit regime is classically verifiable quantum advantage. Achieving this will not only require the jump in quantum device capabilities but also finding advantage schemes that allow for classical verification using these limited resources.
Why is it an interesting and feasible goal and what is it anyway?
To my mind, the biggest weakness of the RCS experiments is the way they are verified. I discussed this extensively in the last posts—verification uses XEB which can be classically spoofed, and only actually measured in the simulatable regime. Really, in a quantum advantage experiment I would want there to be an efficient procedure that will without any reasonable doubt convince us that a computation must have been performed by a quantum computer when we run it. In what I think of as classically verifiable quantum advantage, a (classical) verifier would come up with challenge circuits which they would then send to a quantum server. These would be designed in such a way that once the server returns classical samples from those circuits, the verifier can convince herself that the server must have run a quantum computation.
The theoretical computer scientist’s cartoon of verifying a quantum computer.
This is the jump from a physics-type experiment (the sense in which advantage has been achieved) to a secure protocol that can be used in settings where I do not want to trust the server and the data it provides me with. Such security may also allow a first application of quantum computers: to generate random numbers whose genuine randomness can be certified—a task that is impossible classically.
Here is the problem: On the one hand, we do know of schemes that allow us to classically verify that a computer is quantum and generate random numbers, so called cryptographic proofs of quantumness (PoQ). A proof of quantumness is a highly reliable scheme in that its security relies on well-established cryptography. Their big drawback is that they require a large number of qubits and operations, comparable to the resources required for factoring. On the other hand, the computations we can run in the advantage regime—basically, random circuits—are very resource-efficient but not verifiable.
The 100-logical-qubit regime lies right in the middle, and it seems more than plausible that classically verifiable advantage is possible in this regime. The theory challenge ahead of us is to find it: a quantum advantage scheme that is very resource-efficient like RCS and also classically verifiable like proofs of quantumness.
To achieve verifiable advantage in the 100-logical-qubit regime we need to close the gap between random circuit sampling and proofs of quantumness.
With this in mind, let me spell out some concrete goals that we can achieve using 100 logical qubits on the road to classically verifiable quantum advantage.
1. Demonstrate fault-tolerant quantum advantage
Before we talk about verifiable advantage, the first experiment I would like to see is one that combines the two big achievements of the past years, and shows that quantum advantage and fault-tolerance can be achieved simultaneously. Such an experiment would be similar in type to the RCS experiments, but run on encoded qubits with gate sets that match that encoding. During the computation, noise would be suppressed by correcting for errors using the code. In doing so, we could reach the near-perfect regime of RCS as opposed to the finite-fidelity regime that current RCS experiments operate in (as I discussed in detail in Part 2).
Random circuits with a quantum advantage that are particularly easy to implement fault-tolerantly are so-called IQP circuits. In those circuits, the gates are controlled-NOT gates and diagonal gates, so rotations , which just add a phase to a basis state as . The only “quantumness” comes from the fact that each input qubit is in the superposition state , and that all qubits are measured in the basis. This is an example of an example of an IQP circuit:
An IQP circuit starts from the all- state by applying a Hadamard transform, followed by IQP gates (in this case , some CNOT gates, , some CNOT gates, ) and ends in a measurement in the Hadamard basis.
As it so happens, IQP circuits are already really well understood since one of the first proposals for quantum advantage was based on IQP circuits (VerIQP1), and for a lot of the results in random circuits, we have precursors for IQP circuits, in particular, their ideal and noisy complexity (SimIQP). This is because their near-classical structure makes them relatively easy to study. Most importantly, their outcome probabilities are simple (but exponentially large) sums over phases that can just be read off from which gates are applied in the circuit and we can use well-established classical techniques like Boolean analysis and coding theory to understand those.
IQP gates are natural for fault-tolerance because there are codes in which all the operations involved can be implemented transversally. This means that they only require parallel physical single- or two-qubit gates to implement a logical gate rather than complicated fault-tolerant protocols which are required for universal circuits. This is in stark contrast to universal circuit which require resource-intensive fault-tolerant protocols. Running computations with IQP circuits would also be a step towards running real computations in that they can involve structured components such as cascades of CNOT gates and the like. These show up all over fault-tolerant constructions of algorithmic primitives such as arithmetic or phase estimation circuits.
Our concrete proposal for an IQP-based fault-tolerant quantum advantage experiment in reconfigurable-atom arrays is based on interleaving diagonal gates and CNOT gates to achieve super-fast scrambling (ftIQP1). A medium-size version of this protocol was implemented by the Harvard group (LogicalExp) but with only a bit more effort, it could be performed in the advantage regime.
In those proposals, verification will still suffer from the same problems of standard RCS experiments, so what’s up next is to fix that!
2. Closing the verification loophole
I said that a key milestone for the 100-logical-qubit regime is to find schemes that lie in between RCS and proofs of quantumness in terms of their resource requirements but at the same time allow for more efficient and more convincing verification than RCS. Naturally, there are two ways to approach this space—we can make quantum advantage schemes more verifiable, and we can make proofs of quantumness more resource-efficient.
First, let’s focus on the former approach and set a more moderate goal than full-on classical verification of data from an untrusted server. Are there variants of RCS that allow us to efficiently verify that finite-fidelity RCS has been achieved if we trust the experimenter and the data they hand us?
2.1 Efficient quantum verification using random circuits with symmetries
Indeed, there are! I like to think of the schemes that achieve this as random circuits with symmetries. A symmetry is an operator such that the outcome state of the computation (or some intermediate state) is invariant under the symmetry, so . The idea is then to find circuits that exhibit a quantum advantage and at the same time have symmetries that can be easily measured, say, using only single-qubit measurements or a single gate layer. Then, we can use these measurements to check whether or not the pre-measurement state respects the symmetries. This is a test for whether the quantum computer prepared the correct state, because errors or deviations from the true state would violate the symmetry (unless they were adversarially engineered).
In random circuits with symmetries, we can thus use small, well-characterized measurements whose outcomes we trust to probe whether a large quantum circuit has been run correctly. This is possible in a scenario I call the trusted experimenter scenario.
The trusted experimenter scenario In this scenario, we receive data from an actual experiment in which we trust that certain measurements were actually and correctly performed.
I think of random circuits with symmetries as introducing measurements in the circuit that check for errors.
Here are some examples of random circuits with symmetries, which allow for efficient verification of quantum advantage in the trusted experimenter scenario.
Graph states. My first example are locally rotated graph states (GStates). These are states that are prepared by CZ gates acting according to the edges of a graph on an initial all- state, and a layer of single-qubit -rotations is performed before a measurement in the basis. (Yes, this is also an IQP circuit.) The symmetries of this circuit are locally rotated Pauli operators, and can therefore be measured using only single-qubit rotations and measurements. What is more, these symmetries fully determine the graph state. Determining the fidelity then just amounts to averaging the expectation values of the symmetries, which is so efficient you can even do it in your head. In this example, we need measuring the outcome state to obtain hard-to-reproduce samples and measuring the symmetries are done in two different (single-qubit) bases.
With 100 logical qubits, samples from classically intractable graph states on several 100 qubits could be easily generated.
Bell sampling. The drawback of this approach is that we need to make two different measurements for verification and sampling. But it would be much more neat if we could just verify the correctness of a set of classically hard samples by only using those samples. For an example where this is possible, consider two copies of the output state of a random circuit, so . This state is invariant under a swap of the two copies, and in fact the expectation value of the SWAP operator in a noisy state preparation of determines the purity of the state, so . It turns out that measuring all pairs of qubits in the state in the pairwise basis of the four Bell states , where is one of the four Pauli matrices , this is hard to simulate classically (BellSamp). You may also observe that the SWAP operator is diagonal in the Bell basis, so its expectation value can be extracted from the Bell-basis measurements—our hard to simulate samples. To do this, we just average sign assignments to the samples according to their parity.
If the circuit is random, then under the same assumptions as those used in XEB for random circuits, the purity is a good estimator of the fidelity, so . So here is an example, where efficient verification is possible directly from hard-to-simulate classical samples under the same assumptions as those used to argue that XEB equals fidelity.
With 100 logical qubits, we can achieve quantum advantage which is at least as hard as the current RCS experiments that can also be efficiently (physics-)verified from the classical data.
Fault-tolerant circuits. Finally, suppose that we run a fault-tolerant quantum advantage experiment. Then, there is a natural set of symmetries of the state at any point in the circuit, namely, the stabilizers of the code we use. In a fault-tolerant experiment we repeatedly measure those stabilizers mid-circuit, so why not use that data to assess the quality of the logical state? Indeed, it turns out that the logical fidelity can be estimated efficiently from stabilizer expectation values even in situations in which the logical circuit has a quantum advantage (SyndFid).
With 100 logical qubits, we could therefore just run fault-tolerant IQP circuits in the advantage regime (ftIQP1) and the syndrome data would allow us to estimate the logical fidelity.
In all of these examples of random circuits with symmetries, coming up with classical samples that pass the verification tests is very easy, so the trusted-experimenter scenario is crucial for this to work. (Note, however, that it may be possible to add tests to Bell sampling that make spoofing difficult.) At the same time, these proposals are very resource-efficient in that they only increase the cost of a pure random-circuit experiment by a relatively small amount. What is more, the required circuits have more structure than random circuits in that they typically require gates that are natural in fault-tolerant implementations of quantum algorithms.
Performing random circuit sampling with symmetries is therefore a natural next step en-route to both classically verifiable advantage that closes the no-efficient verification loophole, and towards implementing actual algorithms.
What if we do not want to afford that level of trust in the person who runs the quantum circuit, however?
2.2 Classical verification using random circuits with planted secrets
If we do not trust the experimenter, we are in the untrusted quantum server scenario.
The untrusted quantum server scenario In this scenario, we delegate a quantum computation to an untrusted (presumably remote) quantum server—think of using a Google or Amazon cloud server to run your computation. We can communicate with this server using classical information.
In the untrusted server scenario, we can hope to use ideas from proofs of quantumness such as the use of classical cryptography to design families of quantum circuits in which some secret structure is planted. This secret structure should give the verifier a way to check whether a set of samples passes a certain verification test. At the same time it should not be detectable, or at least not be identifiable from the circuit description alone.
The simplest example of such secret structure could be a large peak in an otherwise flat output distribution of a random-looking quantum circuit. To do this, the verifier would pick a (random) string and design a circuit such that the probability of seeing in samples, is large. If the peak is hidden well, finding it just from the circuit description would require searching through all of the outcome bit strings and even just determining one of the outcome probabilities is exponentially difficult. A classical spoofer trying to fake the samples from a quantum computer would then be caught immediately: the list of samples they hand the verifier will not even contain unless they are unbelievably lucky, since there are exponentially many possible choices of .
Unfortunately, planting such secrets seems to be very difficult using universal circuits, since the output distributions are so unstructured. This is why we have not yet found good candidates of circuits with peaks, but some tries have been made (Peaks,ECPeaks,HPeaks)
We do have a promising candidate, though—IQP circuits! The fact that the output distributions of IQP circuits are quite simple could very well help us design sampling schemes with hidden secrets. Indeed, the idea of hiding peaks has been pioneered by Shepherd and Bremner (VerIQP1) who found a way to design classically hard IQP circuits with a large hidden Fourier coefficient. The presence of this large Fourier coefficient can easily be checked from a few classical samples, and random IQP circuits do not have any large Fourier coefficients. Unfortunately, for that construction and a variation thereof (VerIQP2), it turned out that the large coefficient can be detected quite easily from the circuit description (ClassIQP1,ClassIQP2).
To this day, it remains an exciting open question whether secrets can be planted in (maybe IQP) circuit families in a way that allows for efficient classical verification. Even finding a scheme with some large gap between verification and simulation times would be exciting, because it would for the first time allow us to verify a quantum computing experiment in the advantage regime using only classical computation.
Towards applications: certifiable random number generation
Beyond verified quantum advantage, sampling schemes with hidden secrets may be usable to generate classically certifiable random numbers: You sample from the output distribution of a random circuit with a planted secret, and verify that the samples come from the correct distribution using the secret. If the distribution has sufficiently high entropy, truly random numbers can be extracted from them. The same can be done for RCS, except that some acrobatics are needed to get around the problem that verification is just as costly as simulation (CertRand, CertRandExp). Again, a large gap between verification and simulation times would probably permit such certified random number generation.
The goal here is firstly a theoretical one: Come up with a planted-secret RCS scheme that has a large verification-simulation gap. But then, of course, it is an experimental one: actually perform such an experiment to classically verify quantum advantage.
Should an IQP-based scheme of circuits with secrets exist, 100 logical qubits is the regime where it should give a relevant advantage.
Three milestones
Altogether, I proposed three milestones for the 100 logical qubit regime.
Perform fault-tolerant quantum advantage using random IQP circuits. This will allow an improvement of the fidelity towards performing near-perfect RCS and thus closes the scalability worries of noisy quantum advantage I discussed in my last post.
Perform RCS with symmetries. This will allow for efficient verification of quantum advantage in the trusted experimenter scenario and thus make a first step toward closing the verification loophole.
Find and perform RCS schemes with planted secrets. This will allow us to verify quantum advantage in the remote untrusted server scenario and presumably give a first useful application of quantum computers to generate classically certified random numbers.
All of these experiments are natural steps towards performing actually useful quantum algorithms in that they use more structured circuits than just random universal circuits and can be used to benchmark the performance of the quantum devices in an advantage regime. Moreover, all of them close some loophole of the previous quantum advantage demonstrations, just like follow-up experiments to the first Bell tests have closed the loopholes one by one.
I argued that IQP circuits will play an important role in achieving those milestones since they are a natural circuit family in fault-tolerant constructions and promising candidates for random circuit constructions with planted secrets. Developing a better understanding of the properties of the output distributions of IQP circuits will help us achieve the theory challenges ahead.
Experimentally, the 100 logical qubit regime is exactly the regime to shoot for with those circuits since while IQP circuits are somewhat easier to simulate than universal random circuits, 100 qubits is well in the classically intractable regime.
What I did not talk about
Let me close this mini-series by touching on a few things that I would have liked to discuss more.
First, there is the OTOC experiment by the Google team (OTOC) which has spawned quite a debate. This experiment claims to achieve quantum advantage for an arguably more natural task than sampling, namely, computing expectation values. Computing expectation values is at the heart of quantum-chemistry and condensed-matter applications of quantum computers. And it has the nice property that it is what the Google team called “quantum-verifiable” (and what I would call “hopefully-in-the-future-verifiable”) in the following sense: Suppose we perform an experiment to measure a classically hard expectation value on a noisy device now, and suppose this expectation value actually carries some signal, so it is significantly far away from zero. Once we have a trustworthy quantum computer in the future, we will be able to check that the outcome of this experiment was correct and hence quantum advantage was achieved. There is a lot of interesting science to discuss about the details of this experiment and maybe I will do so in a future post.
Finally, I want to mention an interesting theory challenge that relates to the noise-scaling arguments I discussed in detail in Part 2: The challenge is to understand whether quantum advantage can be achieved in the presence of a constant amount of local noise. What do we know about this? On the one hand, log-depth random circuits with constant local noise are easy to simulate classically (SimIQP,SimRCS), and we have good numerical evidence that random circuits at very low depths are easy to simulate classically even without noise (LowDSim). So is there a depth regime in between the very low depth and the log-depth regime in which quantum advantage persists under constant local noise? Is this maybe even true in a noise regime that does not permit fault-tolerance (see this interesting talk)? In the regime in which fault-tolerance is possible, it turns out that one can construct simple fault-tolerance schemes that do not require any quantum feedback, so there are distributions that are hard to simulate classically even in the presence of constant local noise.
So long, and thanks for all the fish!
I hope that in this mini-series I could convince you that quantum advantage has been achieved. There are some open loopholes but if you are happy with physics-level experimental evidence, then you should be convinced that the RCS experiments of the past years have demonstrated quantum advantage.
As the devices are getting better at a rapid pace, there is a clear goal that I hope will be achieved in the 100-logical-qubit regime: demonstrate fault-tolerant and verifiable advantage (for the experimentalists) and come up with the schemes to do that (for the theorists)! Those experiments would close the loopholes of the current RCS experiments. And they would work as a stepping stone towards actual algorithms in the advantage regime.
I want to end with a huge thanks to Spiros Michalakis, John Preskill and Frederik Hahn who have patiently read and helped me improve these posts!
References
Fault-tolerant quantum advantage
(ftIQP1) Hangleiter, D. et al. Fault-Tolerant Compiling of Classically Hard Instantaneous Quantum Polynomial Circuits on Hypercubes. PRX Quantum6, 020338 (2025).
(LogicalExp) Bluvstein, D. et al. Logical quantum processor based on reconfigurable atom arrays. Nature626, 58–65 (2024).
Random circuits with symmetries
(BellSamp) Hangleiter, D. & Gullans, M. J. Bell Sampling from Quantum Circuits. Phys. Rev. Lett.133, 020601 (2024).
(GStates) Ringbauer, M. et al. Verifiable measurement-based quantum random sampling with trapped ions. Nat Commun16, 1–9 (2025).
(SyndFid) Xiao, X., Hangleiter, D., Bluvstein, D., Lukin, M. D. & Gullans, M. J. In-situ benchmarking of fault-tolerant quantum circuits. I. Clifford circuits. arXiv:2601.21472 II. Circuits with a quantum advantage. (coming soon!)
Verification with planted secrets
(PoQ) Brakerski, Z., Christiano, P., Mahadev, U., Vazirani, U. & Vidick, T. A Cryptographic Test of Quantumness and Certifiable Randomness from a Single Quantum Device. in 2018 IEEE 59th Annual Symposium on Foundations of Computer Science (FOCS) 320–331 (2018).
(VerIQP1) Shepherd, D. & Bremner, M. J. Temporally unstructured quantum computation. Proceedings of the Royal Society of London A: Mathematical, Physical and Engineering Sciences465, 1413–1439 (2009).
(VerIQP2) Bremner, M. J., Cheng, B. & Ji, Z. Instantaneous Quantum Polynomial-Time Sampling and Verifiable Quantum Advantage: Stabilizer Scheme and Classical Security. PRX Quantum6, 020315 (2025).
(ClassIQP1) Kahanamoku-Meyer, G. D. Forging quantum data: classically defeating an IQP-based quantum test. Quantum7, 1107 (2023).
(ClassIQP2) Gross, D. & Hangleiter, D. Secret-Extraction Attacks against Obfuscated Instantaneous Quantum Polynomial-Time Circuits. PRX Quantum6, 020314 (2025).
(Peaks) Aaronson, S. & Zhang, Y. On verifiable quantum advantage with peaked circuit sampling. arXiv:2404.14493
(ECPeaks) Deshpande, A., Fefferman, B., Ghosh, S., Gullans, M. & Hangleiter, D. Peaked quantum advantage using error correction. arXiv:2510.05262
(HPeaks) Gharibyan, H. et al. Heuristic Quantum Advantage with Peaked Circuits. arXiv:2510.25838
Certifiable random numbers
(CertRand) Aaronson, S. & Hung, S.-H. Certified Randomness from Quantum Supremacy. in Proceedings of the 55th Annual ACM Symposium on Theory of Computing 933–944 (Association for Computing Machinery, New York, NY, USA, 2023).
(CertRandExp) Liu, M. et al. Certified randomness amplification by dynamically probing remote random quantum states. arXiv:2511.03686
OTOC
(OTOC) Abanin, D. A. et al. Observation of constructive interference at the edge of quantum ergodicity. Nature646, 825–830 (2025).
Noisy complexity
(SimIQP) Bremner, M. J., Montanaro, A. & Shepherd, D. J. Achieving quantum supremacy with sparse and noisy commuting quantum computations. Quantum1, 8 (2017).
(SimRCS) Aharonov, D., Gao, X., Landau, Z., Liu, Y. & Vazirani, U. A polynomial-time classical algorithm for noisy random circuit sampling. in Proceedings of the 55th Annual ACM Symposium on Theory of Computing 945–957 (2023).
(LowDSim) Napp, J. C., La Placa, R. L., Dalzell, A. M., Brandão, F. G. S. L. & Harrow, A. W. Efficient Classical Simulation of Random Shallow 2D Quantum Circuits. Phys. Rev. X12, 021021 (2022).
My husband and I visited the Library of Congress on the final day of winter break this year. In a corner, we found a facsimile of a hand-drawn map: the world as viewed by sixteenth-century Europeans. North America looked like it had been dieting, having shed landmass relative to the bulk we knew. Australia didn’t appear. Yet the map’s aesthetics hit home: yellowed parchment, handwritten letters, and symbolism abounded. Never mind street view; I began hungering for an “antique” setting on Google maps.
1507 Waldseemüller Map, courtesy of the Library of Congress
Approximately four weeks after that trip, I participated in the release of another map: the publication of the review “Roadmap on quantum thermodynamics” in the journal Quantum Science and Technology. The paper contains 24 chapters, each (apart from the introduction) profiling one opportunity within the field of quantum thermodynamics. My erstwhile postdoc Aleks Lasek and I wrote the chapter about the thermodynamics of incompatibleconservedquantities, as Quantum Frontiers fans1 might guess from earlierblogposts.
Allow me to confess an ignoble truth: upon agreeing to coauthor the roadmap, I doubted whether it would impact the community enough to merit my time. Colleagues had published the book Thermodynamics in the Quantum Regime seven years earlier. Different authors had contributed different chapters, each about one topic on the rise. Did my community need such a similar review so soon after the book’s publication? If I printed a map of a city the last time I visited, should I print another map this time?
Apparently so. I often tout the swiftness with which quantum thermodynamics is developing, yet not even I predicted the appetite for the roadmap. Approximately thirty papers cited the arXiv version of the paper during the first nine months of its life—before the journal publication. I shouldn’t have likened the book and roadmap to maps of a city; I should have likened them to maps of a terra incognita undergoing exploration. Such maps change constantly, let alone over seven years.
A favorite map of mine, from a book
Two trends unite many of the roadmap’s chapters, like a mountain range and a river. First, several chapters focus on experiments. Theorists founded quantum thermodynamics and dominated the field for decades, but experimentalists are turning the tables. Even theory-heavy chapters, like Aleks’s and mine, mention past experiments and experimental opportunities.
Second, several chapters blend quantum thermodynamics with many-body physics. Many-body physicists share interests with quantum thermodynamicists: thermalization and equilibrium, the absence thereof, and temperature. Yet many-body physicists belong to another tribe. They tend to interact with each other differently than quantum thermodynamicists do, write papers differently, adhere to different standards, and deploy different mathematical toolkits. Many-body-physicists use random-matrix theory, mean field theory, Wick transformations, and the like. Quantum thermodynamicists tend to cultivate and apply quantum information theory. Yet the boundary between the communities has blurred, and many scientists (including yours truly) shuttle between the two.
My favorite anti-map, from another book (series)
When Quantum Science and Technology published the roadmap, lead editor Steve Campbell announced the event to us coauthors. He’d wrangled the 69 of us into agreeing to contribute, choosing topics, drafting chapters, adhering to limitations on word counts and citations, responding to referee reports, and editing. An idiom refers to the herding of cats, but it would gain in poignancy by referring to the herding of academics. Little wonder Steve wrote in his email, “I’ll leave it to someone else to pick up the mantle and organise Roadmap #2.” I look forward to seeing that roadmap—and, perhaps, contributing to it. Who wants to pencil in Australia with me?


























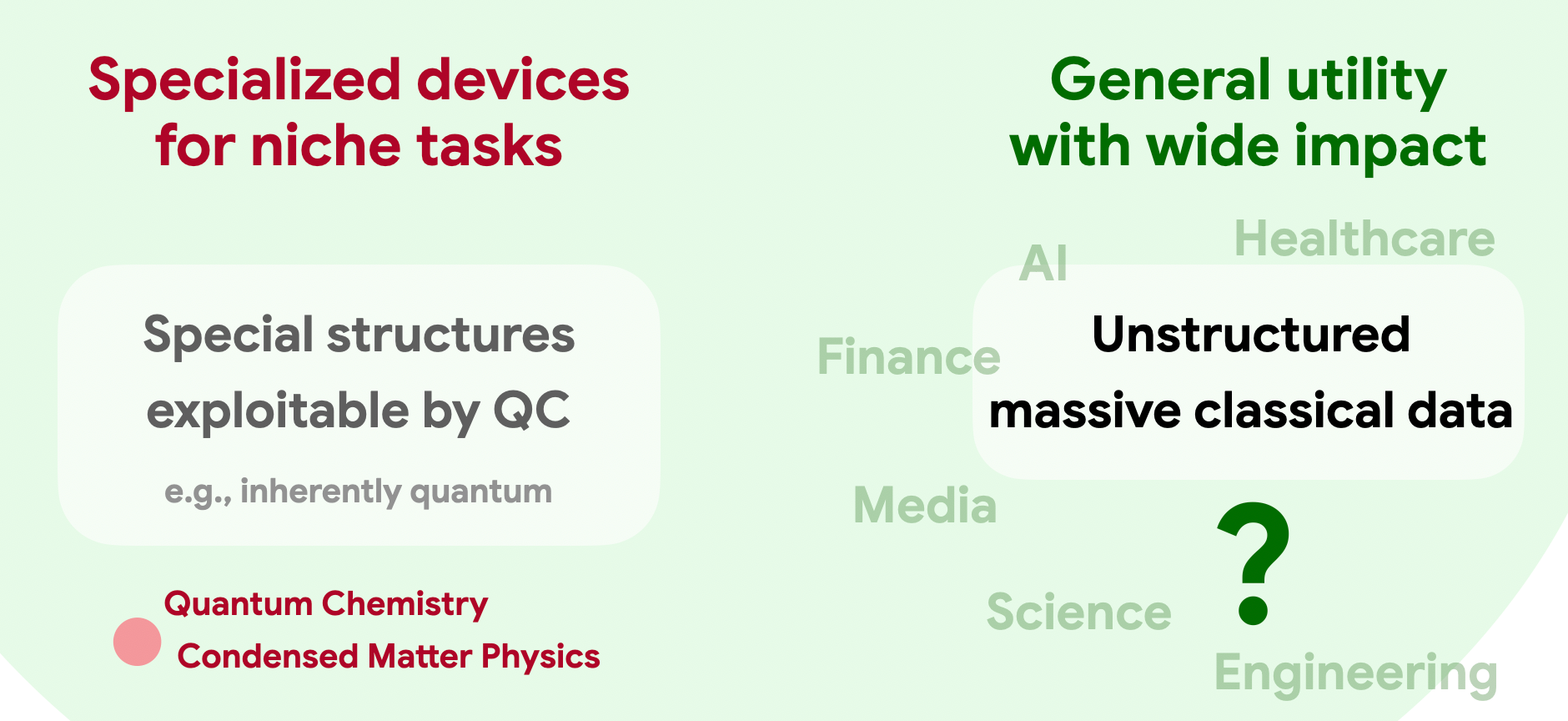
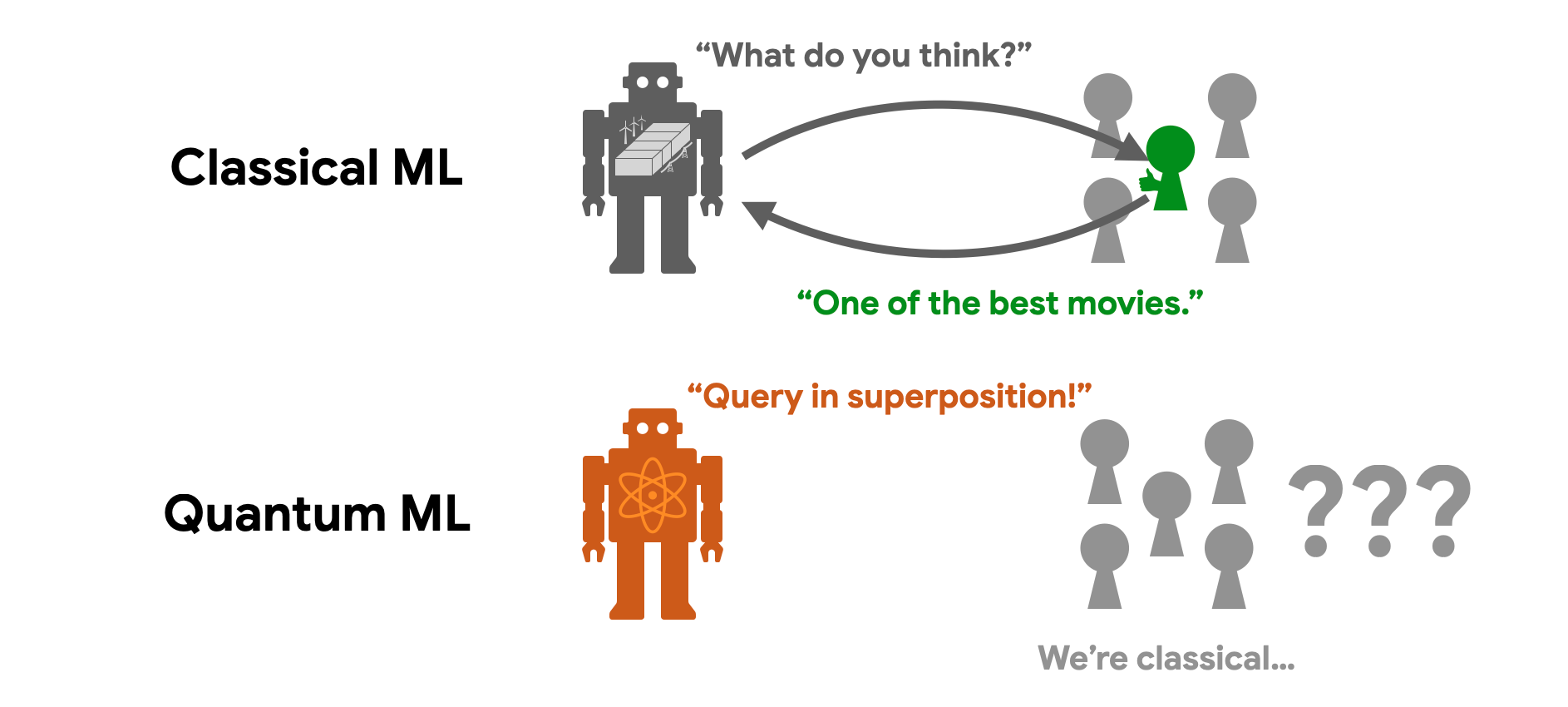

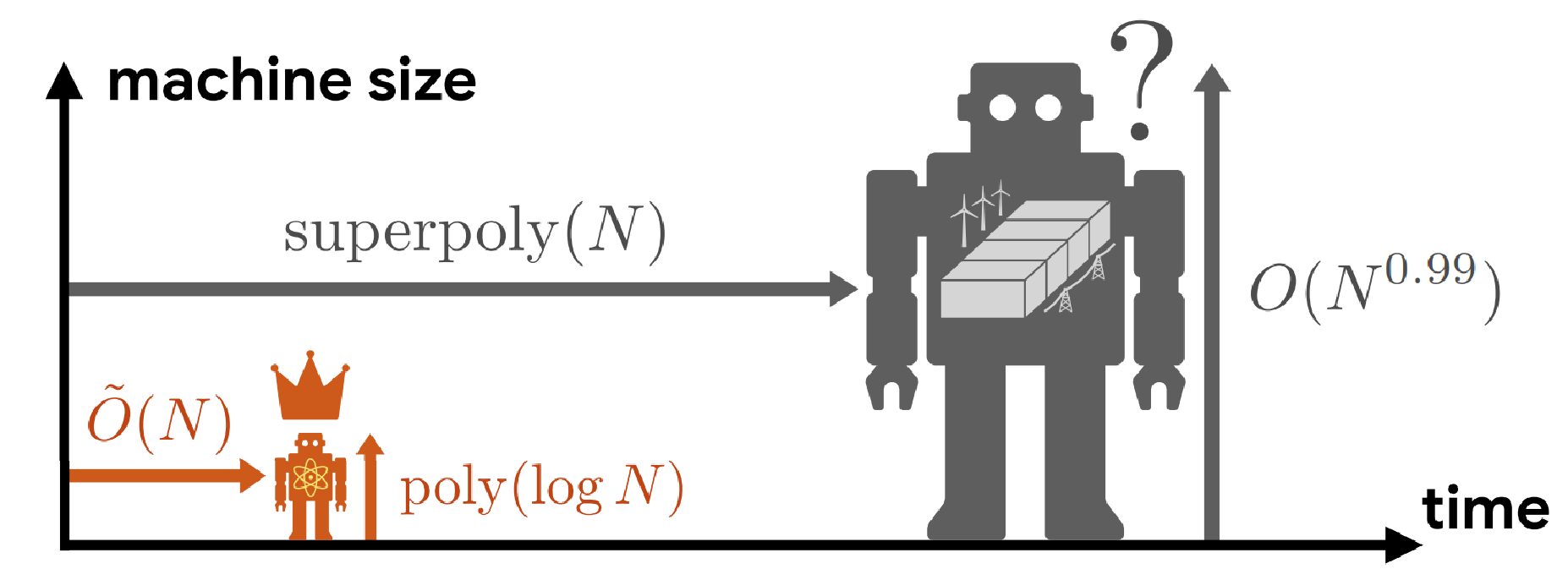

 states (specified by
the underlying basis) which connect to the space of slightly entangled
states with
states (specified by
the underlying basis) which connect to the space of slightly entangled
states with  that the
algorithm naturally explores. In coupled cluster methods, this is the
initial reference state to which excitations are applied. Although many
classical heuristics are exact with exponential effort, e.g. by
increasing the bond dimension
that the
algorithm naturally explores. In coupled cluster methods, this is the
initial reference state to which excitations are applied. Although many
classical heuristics are exact with exponential effort, e.g. by
increasing the bond dimension  in
a tensor network or excitation level in coupled cluster theory, in
practical computational chemistry, classical heuristics are used with
the assumption that so long as the initial state is chosen
appropriately, they will converge rapidly to the true ground-state
without exponential effort. I analyze this heuristic working assumption
in Ref.
in
a tensor network or excitation level in coupled cluster theory, in
practical computational chemistry, classical heuristics are used with
the assumption that so long as the initial state is chosen
appropriately, they will converge rapidly to the true ground-state
without exponential effort. I analyze this heuristic working assumption
in Ref.  spin symmetry. However, as recognized
by Anderson decades ago, for magnetic order in large systems, the
eigenstates can be chosen to break
spin symmetry. However, as recognized
by Anderson decades ago, for magnetic order in large systems, the
eigenstates can be chosen to break  (where
(where  is the system volume). For a finite
energy resolution
is the system volume). For a finite
energy resolution  we can equally use a broken symmetry description
of the states, an example of the fragility of entanglement effects in
physical systems.
we can equally use a broken symmetry description
of the states, an example of the fragility of entanglement effects in
physical systems. changes in the bonding and
chemistry.
changes in the bonding and
chemistry.