
Two weeks into the Football World Cup and the group stages are over: 16 teams have gone home, leaving the top 16 teams to contend the knock-out stages. Those fans who enjoy a bet will be poring over the odds in search of a bargain—a mis-calculation on the part of the bookmakers. Is now the time to back Ronaldo for the golden boot, whilst Harry Kane dominates the headlines and sports betting markets? Will the hosts Russia continue to defy lowly pre-tournament expectations and make the semi-finals? Are France about to emerge from an unconvincing start to the tournament and blossom as clear front-runners?
But, whilst for most the sports betting markets may lead to the enhanced enjoyment of the tournament that a bet can bring (as well as the possibility of making a little money), for others they represent a window into the fascinating world of sports statistics. A fascination that can be captured by the simple question: how do they set the odds?
Suppose that a bookmaker has in their possession a list of outcome probabilities for matches between each pair of national football teams in the world and wants to predict the overall winner. There are 32768 possible ways for the tournament knock-out rounds to pan-out—a large, but not insurmountable number of iterations by modern computational standards.
However, if the bookmaker instead considers the tennis grand-slams, with 128 competitors in the first round, then there are a colossal 1.7 × 1038 permutations. Indeed, in a knock-out format there are 2n-1 permutations, where n is the number of entrants. And for those of a certain mindset, this exponentially growing space immediately raises the question of whether a quantum algorithm can yield a speed-up for the related prediction tasks.
A Tiny Cup
The immediate question which we want to answer here is, perhaps, who will win the World Cup. We will walk through the idea on the blackboard first, and then implement it as a quantum algorithm—which, hopefully, will give some insight into how and where quantum computers can outperform classical ones, for this particular way of answering the question.
Let us take a toy setup with four teams A, B, C and D;
the knockout stage starts with a game A vs. B, and C vs. D.
Whoever wins each game will play against each other, so here we have four possible final games: A vs. C, A vs. D, B vs. C, or B vs. D.
Let’s denote by p(X, Y) the probability that X wins when playing against Y.
The likelihood of A winning the cup is then simply given by
p(A, B) × ( p(C, D) × p(A, C) + p(D, C) × p(A, D) ),
i.e. the probability that A wins against B, times the probabilities of A winning against C in case C won against D, plus the probability of A winning against D in case D won.
How can we obtain the same quantity with a quantum algorithm?
First, we set up our Hilbert space so that it can represent all possible Cup scenarios.
Since we have four teams, we need a four-dimensional quantum system as our smallest storage unit—we commonly call those qudits as generalizations of a qubit, which having dimension 2 would be fit to store two teams only (we can always “embed” a qudit into a few qubits of the same dimension.
Remember: k qubits have dimension 2k, so we could also store the qudit as two qubits).
If we write 

To represent a full knockout tree, we follow the same logic: Take four qudits for the initial draw; add two qudits for the winners of the first two matches, and one qudit for the final winner.
For instance, one possible knockout scenario would be
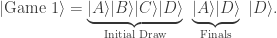
The probability associated with Game 1 is then precisely p(A, B) × p(D, C) × p(D, A).
Here is where quantum computing comes in.
Starting from an initial state 
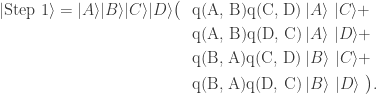
For the final round, we perform the same operation on those two last slots; e.g. we would map 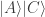

So you can tell me who wins the World Cup?
Yes. Or well, probably. We find out by measuring the rightmost qudit.
As we know, the probability of obtaining a certain measurement outcome, say A, will then be determined by the square of the weights in front of the measured state; since we put in the square-roots initially we recover the original probabilities. Neat!
And since there are two possible game trees that lead to a victory of A, we have to sum them up—and we get precisely the probability we calculated by hand above. This means the team that is most likely to win will be the most likely measurement outcome.
So what about the World Cup? We have 16 teams; one team can thus be stored in four qubits. The knockout tree has 31 vertices, and a naive implementation can be done on a quantum computer with 124 qubits. Of course we are only a bit naive, so we can simulate this quantum computer on a classical one and obtain the following winning probabilities:
| 0.194 | Brazil |
| 0.168 | Spain |
| 0.119 | France |
| 0.092 | Belgium |
| 0.082 | Argentina |
| 0.075 | England |
| 0.049 | Croatia |
| 0.041 | Colombia |
| 0.04 | Portugal |
| 0.032 | Uruguay |
| 0.031 | Russia |
| 0.022 | Switzerland |
| 0.019 | Denmark |
| 0.018 | Sweden |
| 0.012 | Mexico |
| 0.006 | Japan |
It is worth noting that all operations we described can be implemented efficiently with a quantum computer, and the number of required qubits is quite small; for the four teams, we could get away with seven qudits, or fourteen qubits (and we could even save some, by ignoring the first four qudits which are always the same).
So for this particular algorithm there is an exponential speedup over its non-probabilistic classical counterpart: as mentioned, one would have to iterate over all trees; tedious for the World Cup, practically impossible for tennis. However…
Classical vs. Quantum
Does using a quantum algorithm give us a speedup for this task? Here, the answer is no; one could obtain similar results in comparable time using probabilistic methods, for instance, by doing Monte Carlo sampling.
But there are several interesting related questions that we could ask for which there might be a quantum advantage.
For some team A, we can easily create a state that has all game trees in superposition that lead to a victory of A—even weighting them using their respective probabilities.
Given this state as a resource, we can think of questions like “which game tree is most likely, given that we fix A and B as semifinalists”, or “which team should A play in the knockout stages to maximize the probability that B wins the tournament”.
Or, more controversially: can we optimize the winning chances for some team by rearranging the initial draw?
Some questions like these lend themselves to applying Grover search, for which there is a known speedup over classical computers. To inquire deeper into the utility of quantum algorithms, we need to invent the right kind of question to ask of this state.
Let us think of one more toy example. Being part physicists, we assume cows are spheres—so we might as well also assume that if A is likely to win a match against B, it always wins—even if the probability is only 51%. Let’s call this exciting sport “deterministic football”. For a set of teams playing a tournament of deterministic football, does there exist a winning initial draw for every team?
This becomes an especially interesting question in cases where there is a non-trivial cyclic relation between the teams’ abilities, a simple example being: A always beats B, B always beats C, and C always beats A. For example, if this problem turns out to be NP-hard, then it would be reasonable to expect that the quadratic improvement achieved by quantum search is the best we can hope for in using a quantum algorithm for the task of finding a winning initial draw for a chosen team—at least for deterministic football (phew).
To the finals and beyond
World Cup time is an exciting time: whatever the question, we are essentially dealing with binary trees, and making predictions can be translated into finding partitions or cuts that satisfy certain properties defined through a function of the edge weights (here the pairwise winning probabilities). We hope this quantum take on classical bookmaking might point us in the direction of new and interesting applications for quantum algorithms.
Hopefully a good bargain!
(Written with Steven Herbert and Sathyawageeswar Subramanian)


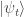 represents a snapshot of the story or calculation at time t—in the division example, this would be the current divisor and remainder terms; so e.g. the snapshot
represents a snapshot of the story or calculation at time t—in the division example, this would be the current divisor and remainder terms; so e.g. the snapshot  represents the initial dividend and divisor, and the person next to you is thinking of
represents the initial dividend and divisor, and the person next to you is thinking of  , one step into the calculation. The label
, one step into the calculation. The label 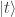 in front of the tensor sign
in front of the tensor sign 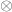 is like a tag that you put on files on your computer, and uniquely associates the snapshot
is like a tag that you put on files on your computer, and uniquely associates the snapshot 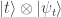 are distinct states (the time labels, if not the story snapshots, are all unique), and by adding these states up we put them into superposition. So if we were to measure the time label, we would obtain one of the snapshots uniformly at random—it’s as if you had a cloth bag full of cards, and you blindly pick one. One side of the card will have the time label on it, while the other side contains the story snapshot. But don’t be fooled—you cannot access all story snapshots by successive measurements! Quantum states collapse; whatever measurement outcome you have dictates what the quantum state will look like after the measurement. In our example, this means that we burn the cloth bag after you pick your card; in this sense, the quantum state behaves differently than a simple juxtaposition of scraps of paper.
are distinct states (the time labels, if not the story snapshots, are all unique), and by adding these states up we put them into superposition. So if we were to measure the time label, we would obtain one of the snapshots uniformly at random—it’s as if you had a cloth bag full of cards, and you blindly pick one. One side of the card will have the time label on it, while the other side contains the story snapshot. But don’t be fooled—you cannot access all story snapshots by successive measurements! Quantum states collapse; whatever measurement outcome you have dictates what the quantum state will look like after the measurement. In our example, this means that we burn the cloth bag after you pick your card; in this sense, the quantum state behaves differently than a simple juxtaposition of scraps of paper. are related to each other in the correct manner, e.g. that your friend on seat t+1 performs a valid division step from the snapshot prepared by the person on seat t. In fancy physics speak (aka Bra-Ket notation), we can for example write
are related to each other in the correct manner, e.g. that your friend on seat t+1 performs a valid division step from the snapshot prepared by the person on seat t. In fancy physics speak (aka Bra-Ket notation), we can for example write
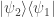 in advance, there would be no use to this construction. So instead, we can write
in advance, there would be no use to this construction. So instead, we can write
 with another desired transition operator (a unitary matrix), we can perform any computation we want (more precisely, any computation that can be written as a unitary matrix; this includes anything your laptop can do). However, this is only half of the story, since we need to have a way of reading out the final answer. So let’s step back for a moment, and go back to the telephone game.
with another desired transition operator (a unitary matrix), we can perform any computation we want (more precisely, any computation that can be written as a unitary matrix; this includes anything your laptop can do). However, this is only half of the story, since we need to have a way of reading out the final answer. So let’s step back for a moment, and go back to the telephone game.



 is an even number. If it isn’t, no bonus is felt; this would correspond to you keeping the dollar you promised to your friend. This simply means that in case the computation has a desirable outcome—i.e. an even number—the Hamiltonian allows a lower energy ground state than for any other output. Et voilà, we can distinguish between different outputs of the computation.
is an even number. If it isn’t, no bonus is felt; this would correspond to you keeping the dollar you promised to your friend. This simply means that in case the computation has a desirable outcome—i.e. an even number—the Hamiltonian allows a lower energy ground state than for any other output. Et voilà, we can distinguish between different outputs of the computation.
 promise gap splitting the embedded YES and NO instances). Why is estimating the ground state energy hard? The energy shift induced by the output penalty depends on the outcome of the computation that we embed (e.g. even or odd outcome). And as fun as long division is, there are much more difficult tasks we can write down as a history state Hamiltonian—in fact, it is this very freedom which makes estimating the ground state energy difficult: if we can embed any computation we want, estimating the induced energy shift should be at least as hard as actually performing the computation on a quantum computer. This has one curious implication: if we don’t expect that we can estimate the ground state energy efficiently, the physical system will take a long time to actually assume its ground state when cooled down, and potentially
promise gap splitting the embedded YES and NO instances). Why is estimating the ground state energy hard? The energy shift induced by the output penalty depends on the outcome of the computation that we embed (e.g. even or odd outcome). And as fun as long division is, there are much more difficult tasks we can write down as a history state Hamiltonian—in fact, it is this very freedom which makes estimating the ground state energy difficult: if we can embed any computation we want, estimating the induced energy shift should be at least as hard as actually performing the computation on a quantum computer. This has one curious implication: if we don’t expect that we can estimate the ground state energy efficiently, the physical system will take a long time to actually assume its ground state when cooled down, and potentially 
