
Last August, Toronto’s Centre for Quantum Information and Quantum Control (CQIQC) gave me 35 minutes to make fun of John Preskill in public. CQIQC was hosting its biannual conference, also called CQIQC, in Toronto. The conference features the awarding of the John Stewart Bell Prize for fundamental quantum physics. The prize derives its name for the thinker who transformed our understanding of entanglement. John received this year’s Bell Prize for identifying, with collaborators, how we can learn about quantum states from surprisingly few trials and measurements.
The organizers invited three Preskillites to present talks in John’s honor: Hoi-Kwong Lo, who’s helped steer quantum cryptography and communications; Daniel Gottesman, who’s helped lay the foundations of quantum error correction; and me. I believe that one of the most fitting ways to honor John is by sharing the most exciting physics you know of. I shared about quantum thermodynamics for (simple models of) nuclear physics, along with ten lessons I learned from John. You can watch the talk here and check out the paper, recently published in Physical Review Letters, for technicalities.

John has illustrated this lesson by wrestling with the black-hole-information paradox, including alongside Stephen Hawking. Quantum information theory has informed quantum thermodynamics, as Quantum Frontiers regulars know. Quantum thermodynamics is the study of work (coordinated energy that we can harness directly) and heat (the energy of random motion). Systems exchange heat with heat reservoirs—large, fixed-temperature systems. As I draft this blog post, for instance, I’m radiating heat into the frigid air in Montreal Trudeau Airport.
So much for quantum information. How about high-energy physics? I’ll include nuclear physics in the category, as many of my Europeans colleagues do. Much of nuclear physics and condensed matter involves gauge theories. A gauge theory is a model that contains more degrees of freedom than the physics it describes. Similarly, a friend’s description of the CN Tower could last twice as long as necessary, due to redundancies. Electrodynamics—the theory behind light bulbs—is a gauge theory. So is quantum chromodynamics, the theory of the strong force that holds together a nucleus’s constituents.
Every gauge theory obeys Gauss’s law. Gauss’s law interrelates the matter at a site to the gauge field around the site. For example, imagine a positive electric charge in empty space. An electric field—a gauge field—points away from the charge at every spot in space. Imagine a sphere that encloses the charge. How much of the electric field is exiting the sphere? The answer depends on the amount of charge inside, according to Gauss’s law.

Gauss’s law interrelates the matter at a site with the gauge field nearby…which is related to the matter at the next site…which is related to the gauge field farther away. So everything depends on everything else. So we can’t easily claim that over here are independent degrees of freedom that form a system of interest, while over there are independent degrees of freedom that form a heat reservoir. So how can we define the heat and work exchanged within a lattice gauge theory? If we can’t, we should start biting our nails: thermodynamics is the queen of the physical theories, a metatheory expected to govern all other theories. But how can we define the quantum thermodynamics of lattice gauge theories? My colleague Zohreh Davoudi and her group asked me this question.

I had the pleasure of addressing the question with five present and recent Marylanders…

…the mention of whom in my CQIQC talk invited…

How did we begin establishing a quantum thermodynamics for lattice gauge theories?

Someone who had a better idea than I, when I embarked upon this project, was my colleague Chris Jarzynski. So did Dvira Segal, a University of Toronto chemist and CQIQC’s director. So did everyone else who’d helped develop the toolkit of strong-coupling thermodynamics. I’d only heard of the toolkit, but I thought it sounded useful for lattice gauge theories, so I invited Chris to my conversations with Zohreh’s group.

Strong-coupling thermodynamics concerns systems that interact strongly with reservoirs. System–reservoir interactions are weak, or encode little energy, throughout much of thermodynamics. For example, I exchange little energy with Montreal Trudeau’s air, relative to the amount of energy inside me. The reason is, I exchange energy only through my skin. My skin forms a small fraction of me because it forms my surface. My surface is much smaller than my volume, which is proportional to the energy inside me. So I couple to Montreal Trudeau’s air weakly.
My surface would be comparable to my volume if I were extremely small—say, a quantum particle. My interaction with the air would encode loads of energy—an amount comparable to the amount inside me. Should we count that interaction energy as part of my energy or as part of the air’s energy? Could we even say that I existed, and had a well-defined form, independently of that interaction energy? Strong-coupling thermodynamics provides a framework for answering these questions.

Little is more basic than the first law of thermodynamics, synopsized as energy conservation. The first law governs how much a system’s internal energy changes during any process. The energy change equals the heat absorbed, plus the work absorbed, by the system. Every formulation of thermodynamics should obey the first law—including strong-coupling thermodynamics.
Which lattice-gauge-theory processes should we study, armed with the toolkit of strong-coupling thermodynamics? My collaborators and I implicitly followed

and

We don’t want to irritate experimentalists by asking them to run difficult protocols. Tom Rosenbaum, on the left of the previous photograph, is a quantum experimentalist. He’s also the president of Caltech, so John has multiple reasons to want not to irritate him.
Quantum experimentalists have run quench protocols on many quantum simulators, or special-purpose quantum computers. During a quench protocol, one changes a feature of the system quickly. For example, many quantum systems consist of particles hopping across a landscape of hills and valleys. One might flatten a hill during a quench.
We focused on a three-step quench protocol: (1) Set the system up in its initial landscape. (2) Quickly change the landscape within a small region. (3) Let the system evolve under its natural dynamics for a long time. Step 2 should cost work. How can we define the amount of work performed? By following

John wrote a blog post about how the typical physicist is a one-trick pony: they know one narrow subject deeply. John prefers to know two subjects. He can apply insights from one field to the other. A two-trick pony can show that Gauss’s law behaves like a strong interaction—that lattice gauge theories are strongly coupled thermodynamic systems. Using strong-coupling thermodynamics, the two-trick pony can define the work (and heat) exchanged within a lattice gauge theory.
An experimentalist can easily measure the amount of work performed,1 we expect, for two reasons. First, the experimentalist need measure only the small region where the landscape changed. Measuring the whole system would be tricky, because it’s so large and it can contain many particles. But an experimentalist can control the small region. Second, we proved an equation that should facilitate experimental measurements. The equation interrelates the work performed1 with a quantity that seems experimentally accessible.
My team applied our work definition to a lattice gauge theory in one spatial dimension—a theory restricted to living on a line, like a caterpillar on a thin rope. You can think of the matter as qubits2 and the gauge field as more qubits. The system looks identical if you flip it upside-down; that is, the theory has a 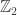

My coauthor Connor simulated the system numerically, calculating its behavior on a classical computer. During the simulated quench process, the system began in one phase (like H
Not only could we define the work exchanged within a lattice gauge theory, using strong-coupling quantum thermodynamics. Also, that work signaled a phase transition—a large-scale, qualitative behavior.

What future do my collaborators and I dream of for our work? First, we want for an experimentalist to measure the work1 spent on a lattice-gauge-theory system in a quantum simulation. Second, we should expand our definitions of quantum work and heat beyond sudden-quench processes. How much work and heat do particles exchange while scattering in particle accelerators, for instance? Third, we hope to identify other phase transitions and macroscopic phenomena using our work and heat definitions. Fourth—most broadly—we want to establish a quantum thermodynamics for lattice gauge theories.

Five years ago, I didn’t expect to be collaborating on lattice gauge theories inspired by nuclear physics. But this work is some of the most exciting I can think of to do. I hope you think it exciting, too. And, more importantly, I hope John thought it exciting in Toronto.

I was a student at Caltech during “One Entangled Evening,” the campus-wide celebration of Richard Feynman’s 100th birthday. So I watched John sing and dance onstage, exhibiting no fear of embarrassing himself. That observation seemed like an appropriate note on which to finish with my slides…and invite questions from the audience.
Congratulations on your Bell Prize, John.
1Really, the dissipated work.
2Really, hardcore bosons.
 copies of a message. Into how few bits (units of information) can I compress the
copies of a message. Into how few bits (units of information) can I compress the 












 quantum particles isolated from its environment. The clump will be in a pure quantum state
quantum particles isolated from its environment. The clump will be in a pure quantum state  at a time
at a time 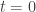 . The particles will interact, evolving the clump’s state as a function
. The particles will interact, evolving the clump’s state as a function  .
. 
 .
. 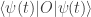 approximately equal to thermal expectation values
approximately equal to thermal expectation values  , for a thermal state
, for a thermal state  of the clump. During
of the clump. During  particles, for some
particles, for some  of our favorite single-particle state
of our favorite single-particle state  . Or we could call any
. Or we could call any 
 , as implied above. The thermal state
, as implied above. The thermal state  , of any quantum state
, of any quantum state  that obeys the same linear constraints as
that obeys the same linear constraints as  -component
-component 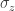 of each qubit’s spin, randomly obtaining a -1 or a 1. One trial yielded a 53-bit string. The experimentalists repeated this process many times, using the same gates in each trial. From all the trials’ bit strings, the group inferred the probability
of each qubit’s spin, randomly obtaining a -1 or a 1. One trial yielded a 53-bit string. The experimentalists repeated this process many times, using the same gates in each trial. From all the trials’ bit strings, the group inferred the probability  of obtaining a given string
of obtaining a given string  in the next trial. The distribution
in the next trial. The distribution  resembles the uniformly random distribution…but differs from it subtly, as revealed by a cross-entropy analysis. Classical computers can’t easily generate
resembles the uniformly random distribution…but differs from it subtly, as revealed by a cross-entropy analysis. Classical computers can’t easily generate 




 -,
-,  -, and
-, and 





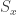 ,
,  , and
, and  . The Hamiltonian obeys the Wigner–Eckart theorem, which sounds more complicated than it is. Suppose that the qubits begin in a state
. The Hamiltonian obeys the Wigner–Eckart theorem, which sounds more complicated than it is. Suppose that the qubits begin in a state  labeled by a spin quantum number
labeled by a spin quantum number 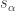 and a magnetic spin quantum number
and a magnetic spin quantum number  . Let a particle hit the qubits, acting on them with an operator
. Let a particle hit the qubits, acting on them with an operator  With what probability (amplitude) do the qubits end up with quantum numbers
With what probability (amplitude) do the qubits end up with quantum numbers  and
and 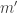 ? The answer is
? The answer is  . The Wigner–Eckart theorem dictates this probability amplitude’s form.
. The Wigner–Eckart theorem dictates this probability amplitude’s form. 
 are Hamiltonian eigenstates, thanks to the conservation law. The ETH is an ansatz for the form of
are Hamiltonian eigenstates, thanks to the conservation law. The ETH is an ansatz for the form of 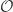 relative to the energy eigenbasis. The ETH butts heads with the Wigner–Eckart theorem, which also predicts the matrix element’s form.
relative to the energy eigenbasis. The ETH butts heads with the Wigner–Eckart theorem, which also predicts the matrix element’s form.
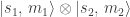 .
. come to equal thermal expectation values
come to equal thermal expectation values  to within
to within  corrections, as I
corrections, as I  , if conserved quantities are incompatible. Our conclusion holds under an assumption that we argue is physically reasonable.
, if conserved quantities are incompatible. Our conclusion holds under an assumption that we argue is physically reasonable.

 . The time-
. The time- state
state 
 .
. 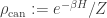 . The average energy
. The average energy 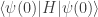 defines the inverse temperature
defines the inverse temperature  , and
, and  normalizes the state. Hence the thermal average is
normalizes the state. Hence the thermal average is 

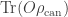 .
. 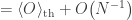 . The correction is small in the total number
. The correction is small in the total number 












