
Several people have asked me whether writing a popular-science book has fed back into my research. Nature Physics published my favorite illustration of the answer this January. Here’s the story behind the paper.
In late 2020, I was sitting by a window in my home office (AKA living room) in Cambridge, Massachusetts. I’d drafted 15 chapters of my book Quantum Steampunk. The epilogue, I’d decided, would outline opportunities for the future of quantum thermodynamics. So I had to come up with opportunities for the future of quantum thermodynamics. The rest of the book had related foundational insights provided by quantum thermodynamics about the universe’s nature. For instance, quantum thermodynamics had sharpened the second law of thermodynamics, which helps explain time’s arrow, into more-precise statements. Conventional thermodynamics had not only provided foundational insights, but also accompanied the Industrial Revolution, a paragon of practicality. Could quantum thermodynamics, too, offer practical upshots?
Quantum thermodynamicists had designed quantum engines, refrigerators, batteries, and ratchets. Some of these devices could outperform their classical counterparts, according to certain metrics. Experimentalists had even realized some of these devices. But the devices weren’t useful. For instance, a simple quantum engine consisted of one atom. I expected such an atom to produce one electronvolt of energy per engine cycle. (A light bulb emits about 1021 electronvolts of light per second.) Cooling the atom down and manipulating it would cost loads more energy. The engine wouldn’t earn its keep.
Autonomous quantum machines offered greater hope for practicality. By autonomous, I mean, not requiring time-dependent external control: nobody need twiddle knobs or push buttons to guide the machine through its operation. Such control requires work—organized, coordinated energy. Rather than receiving work, an autonomous machine accesses a cold environment and a hot environment. Heat—random, disorganized energy cheaper than work—flows from the hot to the cold. The machine transforms some of that heat into work to power itself. That is, the machine sources its own work from cheap heat in its surroundings. Some air conditioners operate according to this principle. So can some quantum machines—autonomous quantum machines.
Thermodynamicists had designed autonomous quantum engines and refrigerators. Trapped-ion experimentalists had realized one of the refrigerators, in a groundbreaking result. Still, the autonomous quantum refrigerator wasn’t practical. Keeping the ion cold and maintaining its quantum behavior required substantial work.
My community needed, I wrote in my epilogue, an analogue of solar panels in southern California. (I probably drafted the epilogue during a Boston winter, thinking wistfully of Pasadena.) If you built a solar panel in SoCal, you could sit back and reap the benefits all year. The panel would fulfill its mission without further effort from you. If you built a solar panel in Rochester, you’d have to scrape snow off of it. Also, the panel would provide energy only a few months per year. The cost might not outweigh the benefit. Quantum thermal machines resembled solar panels in Rochester, I wrote. We needed an analogue of SoCal: an appropriate environment. Most of it would be cold (unlike SoCal), so that maintaining a machine’s quantum nature would cost a user almost no extra energy. The setting should also contain a slightly warmer environment, so that net heat would flow. If you deposited an autonomous quantum machine in such a quantum SoCal, the machine would operate on its own.
Where could we find a quantum SoCal? I had no idea.

A few months later, I received an email from quantum experimentalist Simone Gasparinetti. He was setting up a lab at Chalmers University in Sweden. What, he asked, did I see as opportunities for experimental quantum thermodynamics? We’d never met, but we agreed to Zoom. Quantum Steampunk on my mind, I described my desire for practicality. I described autonomous quantum machines. I described my yearning for a quantum SoCal.
I have it, Simone said.
Simone and his colleagues were building a quantum computer using superconducting qubits. The qubits fit on a chip about the size of my hand. To keep the chip cold, the experimentalists put it in a dilution refrigerator. You’ve probably seen photos of dilution refrigerators from Google, IBM, and the like. The fridges tend to be cylindrical, gold-colored monstrosities from which wires stick out. (That is, they look steampunk.) You can easily develop the impression that the cylinder is a quantum computer, but it’s only the fridge.

The fridge, Simone said, resembles an onion: it has multiple layers. Outer layers are warmer, and inner layers are colder. The quantum computer sits in the innermost layer, so that it behaves as quantum mechanically as possible. But sometimes, even the fridge doesn’t keep the computer cold enough.
Imagine that you’ve finished one quantum computation and you’re preparing for the next. The computer has written quantum information to certain qubits, as you’ve probably written on scrap paper while calculating something in a math class. To prepare for your next math assignment, given limited scrap paper, you’d erase your scrap paper. The quantum computer’s qubits need erasing similarly. Erasing, in this context, means cooling down even more than the dilution refrigerator can manage.
Why not use an autonomous quantum refrigerator to cool the scrap-paper qubits?
I loved the idea, for three reasons. First, we could place the quantum refrigerator beside the quantum computer. The dilution refrigerator would already be cold, for the quantum computations’ sake. Therefore, we wouldn’t have to spend (almost any) extra work on keeping the quantum refrigerator cold. Second, Simone could connect the quantum refrigerator to an outer onion layer via a cable. Heat would flow from the warmer outer layer to the colder inner layer. From the heat, the quantum refrigerator could extract work. The quantum refrigerator would use that work to cool computational qubits—to erase quantum scrap paper. The quantum refrigerator would service the quantum computer. So, third, the quantum refrigerator would qualify as practical.
Over the next three years, we brought that vision to life. (By we, I mostly mean Simone’s group, as my group doesn’t have a lab.)

Postdoc Aamir Ali spearheaded the experiment. Then-master’s student Paul Jamet Suria and PhD student Claudia Castillo-Moreno assisted him. Maryland postdoc Jeffrey M. Epstein began simulating the superconducting qubits numerically, then passed the baton to PhD student José Antonio Marín Guzmán.
The experiment provided a proof of principle: it demonstrated that the quantum refrigerator could operate. The experimentalists didn’t apply the quantum refrigerator in a quantum computation. Also, they didn’t connect the quantum refrigerator to an outer onion layer. Instead, they pumped warm photons to the quantum refrigerator via a cable. But even in such a stripped-down experiment, the quantum refrigerator outperformed my expectations. I thought it would barely lower the “scrap-paper” qubit’s temperature. But that qubit reached a temperature of 22 milliKelvin (mK). For comparison: if the qubit had merely sat in the dilution refrigerator, it would have reached a temperature of 45–70 mK. State-of-the-art protocols had lowered scrap-paper qubits’ temperatures to 40–49 mK. So our quantum refrigerator outperformed our competitors, through the lens of temperature. (Our quantum refrigerator cooled more slowly than they did, though.)
Simone, José Antonio, and I have followed up on our autonomous quantum refrigerator with a forward-looking review about useful autonomous quantum machines. Keep an eye out for a blog post about the review…and for what we hope grows into a subfield.
In summary, yes, publishing a popular-science book can benefit one’s research.






 and
and  —addressing directly the extent of topological protection of the states generated by non-Abelian anyons. Behavior clearly conforming to the trends highlighted above could certify the device as a topological quantum memory. (Personally, I most anxiously await this milestone.)
—addressing directly the extent of topological protection of the states generated by non-Abelian anyons. Behavior clearly conforming to the trends highlighted above could certify the device as a topological quantum memory. (Personally, I most anxiously await this milestone.)












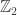 symmetry. The system has two phases, analogous to the liquid and ice phases of H
symmetry. The system has two phases, analogous to the liquid and ice phases of H O. Which phase the system occupies depends on the chemical potential—the average amount of energy needed to add a particle to the system (while the system’s entropy, its volume, and more remain constant).
O. Which phase the system occupies depends on the chemical potential—the average amount of energy needed to add a particle to the system (while the system’s entropy, its volume, and more remain constant).




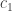 ,
, 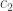 ,
, 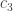 , and
, and 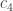 . How accurately can you predict the cell’s location? That is, what probability does the cell have of sitting at some particular site, conditioned on the
. How accurately can you predict the cell’s location? That is, what probability does the cell have of sitting at some particular site, conditioned on the  s? That probability is large only at one site, biophysicists have found empirically. So a cell can accurately infer its position from its molecules’ concentrations.
s? That probability is large only at one site, biophysicists have found empirically. So a cell can accurately infer its position from its molecules’ concentrations.



 denote the cold environment’s temperature; and
denote the cold environment’s temperature; and  , the hot environment’s. The efficiency can’t exceed
, the hot environment’s. The efficiency can’t exceed  . What a simple formula for such an extensive class of objects! Carnot’s theorem governs not only many car engines (Otto engines), but also the
. What a simple formula for such an extensive class of objects! Carnot’s theorem governs not only many car engines (Otto engines), but also the 






