We live in the information revolution. We translate everything into vast sequences of ones and zeroes. From our personal email to our work documents, from our heart rates to our credit rates, from our preferred movies to our movie preferences, all things information are represented using this minimal {0,1} alphabet which our digital helpers “understand” and process. Many of us physicists are now taking this information revolution at heart and embracing the “It from qubit” motto. Our dream: to understand space, time and gravity as emergent features in a world made of information – quantum information.
Over the past two years, I have been obsessively trying to understand this profound perspective more rigorously. Recently, John Preskill and I have taken a further step in this direction in the recent paper: quantum code properties from holographic geometries. In it, we make progress in interpreting features of the holographic approach to quantum gravity in the terms of quantum information constructs.
In this post I would like to present some context for this work through analogies which hopefully help intuitively convey the general ideas. While still containing some technical content, this post is not likely to satisfy those readers seeking a precise in-depth presentation. To you I can only recommend the masterfully delivered lecture notes on gravity and entanglement by Mark Van Raamsdonk.
Entanglement as a cat’s cradle

A cat’s cradle serves as a crude metaphor for quantum mechanical entanglement. The full image provides a complete description of the string and how it is laced in a stable configuration around the two hands. However, this lacing does not describe a stable configuration of half the string on one hand. The string would become disentangled and fall if we were to suddenly remove one of the hands or cut through the middle.
Of all the concepts needed to explain emergent spacetime, maybe the most difficult is that of quantum entanglement. While the word seems to convey some kind of string wound up in a complicated way, it is actually a quality which may describe information in quantum mechanical systems. In particular, it applies to a system for which we have a complete description as a whole, but are only capable of describing certain statistical properties of its parts. In other words, our knowledge of the whole loses predictive power when we are only concerned with the parts. Entanglement entropy is a measure of information which quantifies this.
While our metaphor for entanglement is quite crude, it will serve the purpose of this post. Namely, to illustrate one of the driving premises for the holographic approach to quantum gravity, that the very structure of spacetime is emergent and built up from entanglement entropy.
Knit and crochet your way into the manifolds
But let us bring back our metaphors and try to convey the content of this identification. For this, we resort to the unlikely worlds of knitting and crochet. Indeed, by a planned combination of individual loops and stitches, these traditional crafts are capable of approximating any kind of surface (2D Riemannian surface would be the technical term).

Flat knit (K =0)

Positive curvature crochet (K >0)

Negative curvature crochet (K <0)
Here I have presented some examples with uniform curvature R: flat in green, positive curvature (ball) in yellow and negative curvature (coral reef) in purple. While actual practitioners may be more interested in getting the shape right on hats and socks for loved ones, for us the point is that if we take a step back, these objects built of simple loops, hooks and stitches could end up looking a lot like the smooth surfaces that a physicist might like to use to describe 2D space. This is cute, but can we push this metaphor even further?
Well, first of all, although the pictures above are only representing 2D surfaces, we can expect that a similar approach should allow approximating 3D and even higher dimensional objects (again the technical term is Riemannian manifolds). It would just make things much harder to present in a picture. These woolen structures are, in fact, quite reminiscent of tensor networks, a modern mathematical construct widely used in the field of quantum information. There too, we combine basic building blocks (tensors) through simple operations (tensor index contraction) to build a more complex composite object. In the tensor network world, the structure of the network (how its nodes are connected to other nodes) generically defines the entanglement structure of the resulting object.

This regular tensor network layout was used to describe hyperbolic space which is similar to the purple crochet. However, they apriori look quite dissimilar due to the use of the Poincaré disk model where tensors further from the center look smaller. Another difference is that the high degree of regularity is achieved at the expense of having very few tensors per curvature radius (as compared to its purple crochet cousin). However, planarity and regularity don’t seem to be essential so the crochet probably provides a better intuitive picture.
Roughly speaking, tensor networks are ingenious ways of encoding (quantum) inputs into (quantum) outputs. In particular, if you enter some input at the boundary of your tensor network, the tensors do the work of processing that information throughout the network so that if you ask for an output at any one of the nodes in the bulk of the tensor network, you get the right encoded answer. In other words, the information we input into the tensor network begins its journey at the dangling edges found at the boundary of the network and travels through the bulk edges by exploiting them as information bridges between the nodes of the network.
In the figure representing the cat’s cradle, these dangling input edges can be though of as the fingers holding the wool. Now, if we partition these edges into two disjoint sets (say, the fingers on the left hand and the fingers on the right hand, respectively), there will be some amount of entanglement between them. How much? In general, we cannot say, but under certain assumptions we find that it is proportional to the minimum cut through the network. Imagine you had an incredible number of fingers holding your wool structure. Now separate these fingers arbitrarily into two subsets L and R (we may call them left hand and right hand, although there is nothing right or left handy about them). By pulling left hand and right hand apart, the wool might stretch until at some point it breaks. How many threads will break? Well, the question is analogous to the entanglement one. We might expect, however, that a minimal number of threads break such that each hand can go its own way. This is what we call the minimal cut. In tensor networks, entanglement entropy is always bounded above by such a minimal cut and it has been confirmed that under certain conditions entanglement also reaches, or approximates, this bound. In this respect, our wool analogy seems to be working out.
Holography
Holography, in the context of black holes, was sparked by a profound observation of Jacob Bekenstein and Stephen Hawking, which identified the surface area of a black hole horizon (in Planck units) with its entropy, or information content:
 .
.
Here,  is the entropy associated to the black hole,
is the entropy associated to the black hole,  is its horizon area,
is its horizon area,  is the Planck length and
is the Planck length and  is Boltzmann’s constant.
is Boltzmann’s constant.
Why is this equation such a big deal? Well, there are many reasons, but let me emphasize one. For theoretical physicists, it is common to get rid of physical units by relating them through universal constants. For example, the theory of special relativity allows us to identify units of distance with units of time through the equation  using the speed of light c. General relativity further allows us to identify mass and energy through the famous
using the speed of light c. General relativity further allows us to identify mass and energy through the famous 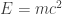 . By considering the Bekenstein-Hawking entropy, units of area are being swept away altogether! They are being identified with dimensionless units of information (one square meter is roughly
. By considering the Bekenstein-Hawking entropy, units of area are being swept away altogether! They are being identified with dimensionless units of information (one square meter is roughly  bits according to the Bousso bound).
bits according to the Bousso bound).
Initially, the identification of area and information was proposed to reconcile black holes with the laws of thermodynamics. However, this has turned out to be the main hint leading to the holographic principle, wherein states that describe a certain volume of space in a theory of quantum gravity can also be thought of as being represented at the lower dimensional boundary of the given volume. This idea, put forth by Gerard ‘t Hooft, was later given a more precise interpretation by Leonard Susskind and subsequently by Juan Maldacena through the celebrated AdS/CFT correspondence. I will not dwell in the details of the AdS/CFT correspondence as I am not an expert myself. However, this correspondence gave S. Ryu and T. Takayanagi (RT) a setting to vastly generalize the identification of area as an information quantity. They proposed identifying the area of minimal surfaces on the bulk (remember the minimal cut?) with entanglement entropy in the boundary theory.
Roughly speaking, if we were to split the boundary into two regions, left  and right
and right  it should be possible to also partition the bulk in a way that each piece of the bulk has either or in its boundary. Ryu and Takayanagi proposed that the area of the smallest surface
it should be possible to also partition the bulk in a way that each piece of the bulk has either or in its boundary. Ryu and Takayanagi proposed that the area of the smallest surface 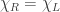 which splits the bulk in this way would be proportional to the entanglement entropy between the two parts
which splits the bulk in this way would be proportional to the entanglement entropy between the two parts
 .
.
It turns out that some quantum field theory states admit such a geometric interpretation. Many high energy theory colleagues have ideas about when this is possible and what are the necessary conditions. By far the best studied setting for this holographic duality is AdS/CFT, where Ryu and Takayanagi first checked their proposal. Here, the entanglement features of the lowest energy state of a conformal field theory are matched to surfaces in a hyperbolic space (like the purple crochet and the tensor network presented). However, other geometries have been shown to match the RT prediction with respect to the entanglement properties of different states. The key point here is that the boundary states do not have any geometry per se. They just manifest different amounts of entanglement when partitioned in different ways.
Emergence
The holographic program suggests that bulk geometry emerges from the entanglement properties of the boundary state. Spacetime materializes from the information structure of the boundary instead of being a fundamental structure as in general relativity. Am I saying that we should strip everything physical, including space in favor of ones and zeros? Well, first of all, it is not just me who is pushing this approach. Secondly, no one is claiming that we should start making all our physical reasoning in terms of ones and zeros.
Let me give an example. We know that the sea is composed mostly of water molecules. The observation of waves that travel, superpose and break can be labeled as an emergent phenomenon. However, to a surfer, a wave is much more real than the water molecules composing it and the fact that it is emergent is of no practical consequence when trying to predict where a wave will break. A proficient physicist, armed with tools from statistical mechanics (there are more than  molecules per liter), could probably derive a macroscopic model for waves from the microscopic theory of particles. In the process of learning what the surfer already understood, he would identify elements of the microscopic theory which become irrelevant for such questions. Such details could be whether the sea has an odd or even number of molecules or the presence of a few fish.
molecules per liter), could probably derive a macroscopic model for waves from the microscopic theory of particles. In the process of learning what the surfer already understood, he would identify elements of the microscopic theory which become irrelevant for such questions. Such details could be whether the sea has an odd or even number of molecules or the presence of a few fish.
In the case of holography, each square meter corresponds to bits of entanglement. We don’t even have words to describe anything close to this outrageously large exponent which leaves plenty of room for emergence. Even taking all the information on the internet – estimated at 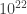 bits (10 zettabits) – we can’t even match the area equivalent of the smallest known particle. The fact that there are so many orders of magnitude makes it difficult to extrapolate our understanding of the geometric domain to the information domain and vice versa. This is precisely the realm where techniques such as those from statistical mechanics successfully get rid of irrelevant details.
bits (10 zettabits) – we can’t even match the area equivalent of the smallest known particle. The fact that there are so many orders of magnitude makes it difficult to extrapolate our understanding of the geometric domain to the information domain and vice versa. This is precisely the realm where techniques such as those from statistical mechanics successfully get rid of irrelevant details.
High energy theorists and people with a background in general relativity tend to picture things in a continuum language. For example, part of their daily butter are Riemannian or Lorentzian manifolds which are respectively used to describe space and spacetime. In contrast, most of information theory is usually applied to deal with discrete elements such as bits, elementary circuit gates, etc. Nevertheless, I believe it is fruitful to straddle this cultural divide to the benefit of both parties. In a way, the convergence we are seeking is analogous to the one achieved by the kinetic theory of gases, which allowed the unification of thermodynamics with classical mechanics.
So what did we do?
The remarkable success of the geometric RT prediction to different bulk geometries such as the BTZ black holes and the generality of the entanglement result for its random tensor network cousins emboldened us to take the RT prescription beyond its usual domain of application. We considered applying it to arbitrary Riemannian manifolds that are space-like and that can be approximated by a smoothly knit fabric.
Furthermore, we went on to consider the implications that such assumptions would have when the corresponding geometries are interpreted as error-correcting codes. In fact, our work elaborates on the perspective of A. Almheiri, X. Dong and D. Harlow (ADH) where quantum error-correcting code properties of AdS/CFT were laid out; it is hard to overemphasize the influence of this work. Our work considers general geometries and identifies properties a code associated to a specific holographic geometry should satisfy.
In the cat cradle/fabric metaphor for holography, the fingers at the boundary constitute the boundary theory without gravity and the resulted fabric represents a bulk geometry in the corresponding bulk gravitational theory. Bulk observables may be represented in different ways on the boundary, but not arbitrarily. This raises the question of which parts of the bulk correspond to which parts of the boundary. In general, there is not a one to one mapping. However, if we partition the boundary in two parts and , we expect to be able to split the bulk into two corresponding regions ![{\mathcal E}[L]](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+E%7D%5BL%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![{\mathcal E}[R]](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+E%7D%5BR%5D&bg=ffffff&fg=333333&s=0&c=20201002) . This is the content of the entanglement wedge hypothesis, which is our other main assumption. In our metaphor, one could imagine that we pull the left fingers up and the right fingers down (taking care not to get hurt). At some point, the fabric breaks through
. This is the content of the entanglement wedge hypothesis, which is our other main assumption. In our metaphor, one could imagine that we pull the left fingers up and the right fingers down (taking care not to get hurt). At some point, the fabric breaks through  into two pieces. In the setting we are concerned with, these pieces maintain part of the original structure, which tells us which bulk information was available in one piece of the boundary and which part was available in the other.
into two pieces. In the setting we are concerned with, these pieces maintain part of the original structure, which tells us which bulk information was available in one piece of the boundary and which part was available in the other.
Although we do not produce new explicit examples of such codes, we worked our way towards developing a language which translates between the holographic/geometric perspective and the coding theory perspective. We specifically build upon the language of operator algebra quantum error correction (OAQEC) which allows individually focusing on different parts of the logical message. In doing so we identified several coding theoretic bounds and quantities, some of which we found to be applicable beyond the context of holography. A particularly noteworthy one is a strengthening of the quantum Singleton bound, which defines a trade-off between how much logical information can be packed in a code, how much physical space is used for encoding this information and how well-protected the information is from erasures.
One of the central observations of ADH highlights how quantum codes have properties from both classical error-correcting codes and secret sharing schemes. On the one hand, logical encoded information should be protected from loss of small parts of the carrier, a property quantified by the code distance. On the other hand, the logical encoded information should not become accessible until a sufficiently large part of the carrier is available to us. This is quantified by the threshold of a corresponding secret sharing scheme. We call this quantity price as it identifies how much of the carrier we would need before someone could reconstruct the message faithfully. In general, it is hard to balance these two competing requirements; a statement which can be made rigorous. This kind of complementarity has long been recognized in quantum cryptography. However, we found that according to holographic predictions, codes admitting a geometric interpretation achieve a remarkable optimality in the trade-off between these features.
Our exploration of alternative geometries is rewarded by the following guidelines

In uberholography, bulk observables are accessible in a Cantor type fractal shaped subregion of the boundary. This is illustrated on the Poincare disc presentation of negatively curved bulk.
- Hyperbolic geometries predict a fixed polynomial scaling for code distance. This is illustrated by a feature we call uberholography. We use this name because there is an excess of holography wherein bulk observables can be represented on intricate subsets of the boundary which have fractal dimension even smaller than the boundary itself.
- Hyperbolic geometries suggest the possibility of decoding procedures which are local on the boundary geometry. This property may be connected to the locality of the corresponding boundary field theory.
- Flat and positive curvature geometries may lead to codes with better parameters in terms of distance and rates (ratio of logical information to physical information). A hemisphere reaches optimum parameters, saturating coding bounds.

Seven iterations of a ternary Cantor set (dark line) on the unit interval. Each iteration is obtained by punching holes from the previous one and the set obtained in the limit is a fractal.
Current day quantum computers are far from the number of qubits required to invoke an emergent geometry. Nevertheless, it is exhilarating to take a step back and consider how the properties of the codes, and information in general, may be interpreted geometrically. On the other hand, I find that the quantum code language we adapt to the context of holography might eventually serve as a useful tool in distinguishing which boundary features are relevant or irrelevant for the emergent properties of the holographic dual. Ours is but one contribution in a very active field. However, the one thing I am certain about is that these are exciting times to be doing physics.



























 . Unfortunately, any obfuscation by compiling scheme has the problem that whoever understands the compiler well enough will be able to actually read the .out file (or notice a pattern in braids reduced to a compact “normal” form), and guess your number without resorting to a quantum computer. Surprisingly, even though Alagic et al.’s scheme doesn’t claim any protection under this attack, it still satisfies one of the theoretical definitions of obfuscation: if two people write two different sets of instructions to perform the same operation, and then each obfuscate their own set of instructions by a restricted set of tricks, then it should be impossible to tell from the end result which program was obtained by whom.
. Unfortunately, any obfuscation by compiling scheme has the problem that whoever understands the compiler well enough will be able to actually read the .out file (or notice a pattern in braids reduced to a compact “normal” form), and guess your number without resorting to a quantum computer. Surprisingly, even though Alagic et al.’s scheme doesn’t claim any protection under this attack, it still satisfies one of the theoretical definitions of obfuscation: if two people write two different sets of instructions to perform the same operation, and then each obfuscate their own set of instructions by a restricted set of tricks, then it should be impossible to tell from the end result which program was obtained by whom.


