
Summer is a great time for academics. Imagine: three full months off! Hit the beach. Tune that golf pitch. Hike the sierras. Go on a cruise. Watch soccer with the brazilenos (there’s been better years for that one). Catch the sunset by the Sydney opera house. Take a nap.

A visiting researcher taking full advantage of the Simons Institute’s world-class relaxation facilities. And yes, I bet you he’s proving a theorem at the same time.
Think that’s outrageous? We have it even better. Not only do we get to travel the globe worry-free, but we prove theorems while doing it. For some of us summer is the only time of year when we manage to prove theorems. Ideas accumulate during the year, blossom during the conferences and workshops that mark the start of the summer, and hatch during the few weeks that many of us set aside as “quiet time” to finally “wrap things up”.
I recently had the pleasure of contributing to the general well-being of my academic colleagues by helping to co-organize (with Andrew Childs, Ignacio Cirac, and Umesh Vazirani) a 2-month long program on “Challenges in Quantum Computation” at the Simons Institute in Berkeley. In this post I report on the program and describe one of the highlights discussed during it: Mahadev’s very recent breakthrough on classical verification of quantum computation.
Challenges in Quantum Computation
The Simons Institute has been in place on the UC Berkeley campus since the Fall of 2013, and in fact one of their first programs was on “Quantum Hamiltonian Complexity”, in Spring 2014 (see my account of one of the semester’s workshops here). Since then the institute has been hosting a pair of semester-long programs at a time, in all areas of theoretical computer science and neighboring fields. Our “summer cluster” had a slightly different flavor: shorter, smaller, it doubled up as the prelude to a full semester-long program scheduled for Spring 2020 (provisional title: The Quantum Wave in Computing, a title inspired from Umesh Vazirani’s recent tutorial at STOC’18 in Los Angeles) — (my interpretation of) the idea being that the ongoing surge in experimental capabilities supports a much broader overhaul of some of the central questions of computer science, from the more applied (such as, programming languages and compilers), to the most theoretical (such as, what complexity classes play the most central role).
This summer’s program hosted a couple dozen participants at a time. Some stayed for the full 2 months, while others visited for shorter times. The Simons Institute is a fantastic place for collaborative research. The three-story building is entirely devoted to us. There are pleasant yet not-too-comfortable shared offices, but the highlight is the two large communal rooms meant for organized and spontaneous discussion. Filled with whiteboards, bright daylight, comfy couches, a constant supply of tea, coffee, and cookies, and eager theorists!
After a couple weeks of settling down the program kicked off with an invigorating workshop. Our goal for the workshop was to frame the theoretical questions raised by the sudden jump in the capabilities of experimental quantum devices that we are all witnessing. There were talks describing progress in experiments (superconducting qubits, ion traps, and cold atoms were represented), suggesting applications for the new devices (from quantum simulation & quantum chemistry to quantum optimization and machine learning through “quantum supremacy” and randomness generation), and laying the theoretical framework for trustworthy interaction with the quantum devices (interactive proofs, testing, and verifiable delegation). We had an outstanding line-up of speakers. All talks (except the panel discussions, unfortunately) were recorded, and you can watch them here.
The workshop was followed by five additional weeks of “residency”, that allowed long-term participants to digest and develop the ideas presented during the workshop. In my experience these few additional weeks, right after the workshop, make all the difference. It is the same difference as between a quick conference call and a leisurely afternoon at the whiteboard: while the former may feel productive and bring the adrenaline levels up, the latter is more suited to in-depth exploration and unexpected discoveries.
There would be much to say about the ideas discussed during the workshop and following weeks. I will describe a single one of these ideas — in my opinion, one of the most outstanding ideas to have emerged at the interface of quantum computing and theoretical computer science in recent years! The result, “Classical Verification of Quantum Computations”, is by Urmila Mahadev, a Ph.D.~student at UC Berkeley (I think she just graduated). Urmila gave a wonderful talk on her result at the workshop, and I highly recommend watching the recorded video. In the remainder of this post I’ll provide an overview of the result. I also wrote a slightly more technical introduction that eager readers will find here.
A cryptographic leash on quantum systems
Mahadev’s result is already famous: announced on the blog of Scott Aaronson, it has earned her a long-standing 25$ prize, awarded for “solving the problem of proving the results of an arbitrary quantum computation to a classical skeptic”. Or, in complexity-theoretic linguo, for showing that “every language in the class BQP admits an interactive protocol where the prover is in BQP and the verifier is in BPP”. What does this mean?
Verifying quantum computations in the high complexity regime
On his blog Scott Aaronson traces the question back to a talk given by Daniel Gottesman in 2004. An eloquent formulation appears in a subsequent paper by Dorit Aharonov and Umesh Vazirani, aptly titled “Is Quantum Mechanics Falsifiable? A computational perspective on the foundations of Quantum Mechanics”.
Here is the problem. As readers of this blog are well aware, Feynman’s idea of a quantum computer, and the subsequent formalization by Bernstein and Vazirani of the Quantum Turing Machine, layed the theoretical foundation for the construction of computing devices whose inner functioning is based on the laws of quantum physics. Most readers also probably realize that we currently believe that these quantum devices will have the ability to efficiently solve computational problems (the class of which is denoted BQP) that are thought to be beyond the reach of classical computers (represented by the class BPP). A prominent example is factoring, but there are many others. The most elementary example is arguably Feynman’s original proposal: a quantum computer can be used to simulate the evolution of any quantum mechanical system “in real time”. In contrast, the best classical simulations available can take exponential time to converge even on concrete examples of practical interest. This places a computational impediment to scientific progress: the work of many physicists, chemists, and biologists, would be greatly sped up if only they could perform simulations at will.
So this hypothetical quantum device claims (or will likely claim) that it has the ability to efficiently solve computational problems for which there is no known efficient classical algorithm. Not only this but, as is widely believed in complexity-theoretic circles (a belief recently strenghtened by the proof of an oracle separation between BQP and PH by Tal and Raz), for some of these problems, even given the answer, there does not exist a classical proof that the answer is correct. The quantum device’s claim cannot be verified! This seems to place the future of science at the mercy of an ingenuous charlatan, with good enough design & marketing skills, that would convince us that it is providing the solution to exponentially complex problems by throwing stardust in our eyes. (Wait, did this happen already?)
Today is the most exciting time in quantum computing since the discovery of Shor’s algorithm for factoring: while we’re not quite ready to run that particular algorithm yet, experimental capabilities have ramped up to the point where we are just about to probe the “high-complexity” regime of quantum mechanics, by making predictions that cannot be emulated, or even verified, using the most powerful classical supercomputers available. What confidence will we have that the predictions have been obtained correctly? Note that this question is different from the question of testing the validity of the theory of quantum mechanics itself. The result presented here assumes the validity of quantum mechanics. What it offers is a method to test, assuming the correctness of quantum mechanics, that a device performs the calculation that it claims to have performed. If the device has supra-quantum powers, all bets are off. Even assuming the correctness of quantum mechanics, however, the device may, intentionally or not (e.g. due to faulty hardware), mislead the experimentalist. This is the scenario that Mahadev’s result aims to counter.
Interactive proofs
The first key idea is to use the power of interaction. The situation can be framed as follows: given a certain computation, such that a device (henceforth called “prover”) has the ability to perform the computation, but another entity, the classical physicist (henceforth called “verifier”) does not, is there a way for the verifier to extract the right answer from the prover with high confidence — given that the prover may not be trusted, and may attempt to use its superior computing power to mislead the verifier instead of performing the required computation?
The simplest scenario would be one where the verifier can execute the computation herself, and check the prover’s outcome. The second simplest scenario is one where the verifier cannot execute the computation, but there is a short proof that the prover can provide that allows her to fully certify the outcome. These two scenario correspond to problems in BPP and NP respectively; an example of the latter is factoring. As argued earlier, not all quantum computations (BQP) are believed to fall within these two classes. Both direct computation and proof verification are ruled out. What can we do? Use interaction!
The framework of interactive proofs originates in complexity theory in the 1990s. An interactive proof is a protocol through which a verifier (typically a computationally bounded entity, such as the physicist and her classical laptop) interacts with a more powerful, but generally untrusted, prover (such as the experimental quantum device). The goal of the protocol is for the verifier to certify the validity of a certain computational statement.
Here is a classical example (the expert — or impatient — reader may safely skip this). The example is for a problem that lies in co-NP, but is not believed to lie in NP. Suppose that both the verifier and prover have access to two graphs, 


A deep result from the 1990s exactly charaterizes the class of computational problems (languages) that a classical polynomial-time verifier can decide in this model: IP = PSPACE. In words, any problem whose solution can be found in polynomial space has an interactive proof in which the verifier only needs polynomial time. Now observe that PSPACE contains NP, and much more: in fact PSPACE contains BQP as well (and even QMA)! (See this nice recent article in Quanta for a gentle introduction to these complexity classes, and more.) Thus any problem that can be decided on a quantum computer can also be decided without a quantum computer, by interacting with a powerful entity, the prover, that can convince the verifier of the right answer without being able to induce her in error (in spite of the prover’s greater power).
Are we not done? We’re not! The problem is that the result PSPACE = IP, even when specialized to BQP, requires (for all we know) a prover whose power matches that of PSPACE (almost: see e.g. this recent result for a slighlty more efficient prover). And as much as our experimental quantum device inches towards the power of BQP, we certainly wouldn’t dare ask it to perform a PSPACE-hard computation. So even though in principle there do exist interactive proofs for BQP-complete languages, these interactive proofs require a prover whose computational power goes much beyond what we believe is physically achievable. But that’s useless (for us): back to square zero.
Interactive proofs with quantum provers
Prior to Mahadev’s result, a sequence of beautiful results in the late 2000’s introduced a clever extension of the model of interactive proofs by allowing the verifier to make use of a very limited quantum computer. For example, the verifier may have the ability to prepare single qubits in two possible bases of her choice, one qubit at a time, and send them to the prover. Or the verifier may have the ability to receive single qubits from the prover, one at a time, and measure them in one of two bases of her choice. In both cases it was shown that the verifier could combine such limited quantum capacity with the possibility to interact with a quantum polynomial-time prover to verify arbitrary polynomial-time quantum computation. The idea for the protocols crucially relied on the ability of the verifier to prepare qubits in a way that any deviation by the prover from the presecribed honest behavior would be detected (e.g. by encoding information in mutually unbiased bases unknown to the prover). For a decade the question remained open: can a completely classical verifier certify the computation performed by a quantum prover?
Mahadev’s result brings a positive resolution to this question. Mahadev describes a protocol with the following properties. First, as expected, for any quantum computation, there is a quantum prover that will convince the classical verifier of the right outcome for the computation. This property is called completeness of the protocol. Second, no prover can convince the classical verifier to accept a wrong outcome. This property is called soundness of the protocol. In Mahadev’s result the latter property comes with a twist: soundness holds provided the prover cannot break post-quantum cryptography. In contrast, the earlier results mentioned in the previous paragraph obtained protocols that were sound against an arbitrarily powerful prover. The additional cryptographic assumption gives Mahadev’s result a “win-win” flavor: either the protocol is sound, or someone in the quantum cloud has figured out how to break an increasingly standard cryptographic assumption (namely, post-quantum security of the Learning With Errors problem) — in all cases, a verified quantum feat!
In the remaining of the post I will give a high-level overview of Mahadev’s protocol and its analysis. For more detail, see the accompanying blog post.
The protocol is constructed in two steps. The first step builds on insights from works preceding this one. This step reduces the problem of verifying the outcome of an arbitrary quantum computation to a seemingly much simpler problem, that nevertheless encapsulates all the subtlety of the verification task. The problem is the following — in keeping with the terminology employed by Mahadev, I’ll call it the qubit commitment problem. Suppose that a prover claims to have prepared a single-qubit state of its choice; call it 
The reduction that accomplishes this first step combines Kitaev’s circuit-to-Hamiltonian construction with some gadgetry from perturbation theory, and I will not describe it here. An important property of the reduction is that it is ultimately sufficient that the verifier has the guarantee that the measurement outcomes she obtains in either case, computational or Hadamard, are consistent with measurement outcomes for the correct measurements performed on some quantum state. In principle the state does not need to be related to anything the prover does (though of course the analysis will eventually define that state from the prover), it only needs to exist. Specifically, we wish to rule out situations where e.g. the prover claims that both outcomes are deterministically “0”, a claim that would violate the uncertainty principle. (For the sake of the argument, let’s ignore that in the case of a single qubit the space of outcomes allowed by quantum mechanics can be explicitly mapped out — in the actual protocol, the prover commits to 
Committing to a qubit
The second step of the protocol construction introduces a key idea. In order to accomplish the sought-after commitment, the verifier is going to engage in an initial commitment phase with the prover. In this phase, the prover is required to provide classical information to the verifier, that “commits” it to a specific qubit. This committed qubit is the state on which the prover will later perform the measurement asked by the verifier. The classical information obtained in the commitment phase will bind the prover to reporting the correct outcome, for both of the verifier’s basis choice — or risk being caught cheating.
How does this work? Commitments to bits, or even qubits, are an old story in cryptography. The standard method for committing to a bit 













What is new in Mahadev’s scheme is not only that the commitment is to a qubit, instead of a bit, but even more importabtly that the commitment is provided by classical information, which is necessary to obtain a classical protocol. (Commitments to qubits, using qubits, can be obtained by combining the quantum one-time pad with the commitment scheme described above.) To explain how this is achieved we’ll need a slightly more advanced crypographic primitive: a pair of injective trapdoor one-way functions 
The commitment phase of the protocol works as follows. Starting from a state 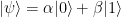
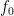
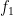

where 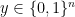
In what sense is 

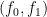
It is such a wonderful idea! It stuns me every time Urmila explains it. Proving it is of course rather delicate. In this post I make an attempt at going into the idea in a little more depth. The best resource remains Urmila’s paper, as well as her talk at the Simons Institute.
Open questions
What is great about this result is not that it closes a decades-old open question, but that by introducing a truly novel idea it opens up a whole new field of investigation. Some of the ideas that led to the result were already fleshed out by Mahadev in her work on homomorphic encryption for quantum circuits, and I expect many more results to continue building on these ideas.
An obvious outstanding question is whether the cryptography is needed at all: could there be a scheme achieving the same result as Mahadev’s, but without computational assumptions on the prover? It is known that if such a scheme exists, it is unlikely to have the property of being blind, meaning that the prover learns nothing about the computation that the verifier wishes it to execute (aside from an upper bound on its length); see this paper for “implausibility” results in this direction. Mahadev’s protocol relies on “post-hoc” verification, and is not blind. Urmila points out that it is likely the protocol could be made blind by composing it with her protocol for homomorphic encryption. Could there be a different protocol, that would not go through post-hoc verification, but instead directly guide the prover through the evaluation of a universal circuit on an encrypted input, gate by gate, as did some previous works?



 , this simply stands for a qudit representing team A; if we write
, this simply stands for a qudit representing team A; if we write  , then we have a state representing two teams.
, then we have a state representing two teams.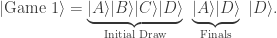
 , we create two new slots in a superposition over all possible match outcomes, weighted by the square-root of their probabilities (which we call q instead of p):
, we create two new slots in a superposition over all possible match outcomes, weighted by the square-root of their probabilities (which we call q instead of p):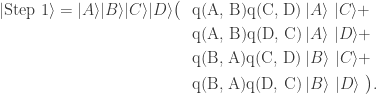
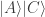 to a state
to a state  . The final state is thus a superposition over eight possible weighted games (as we would expect).
. The final state is thus a superposition over eight possible weighted games (as we would expect).
 required to stretch a spring depends on the spring’s stiffness (the gunk’s viscosity) and on the distance stretched through.
required to stretch a spring depends on the spring’s stiffness (the gunk’s viscosity) and on the distance stretched through.
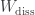 .
. . Consider the greatest
. Consider the greatest 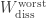 is proportional to each of three information-theoretic quantities, my coauthors and I proved.
is proportional to each of three information-theoretic quantities, my coauthors and I proved. . The Rényi divergences generalize the relative entropy
. The Rényi divergences generalize the relative entropy  .
.  quantifies how efficiently one can distinguish between probability distributions, or quantum states,
quantifies how efficiently one can distinguish between probability distributions, or quantum states,  and
and  on average. The average is over many runs of a guessing game.
on average. The average is over many runs of a guessing game.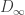 quantifies your likelihood of winning.
quantifies your likelihood of winning. 



 , wherein
, wherein  denotes the probability that the next trial will yield position
denotes the probability that the next trial will yield position  .
.
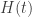 denote the Hamiltonian that evolves with the time
denote the Hamiltonian that evolves with the time ![t \in [0, t_f]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C+t_f%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Consider preparing the system in an energy eigenstate
. Consider preparing the system in an energy eigenstate 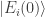 . This state has zero diagonal entropy: Measuring the energy yields
. This state has zero diagonal entropy: Measuring the energy yields  deterministically. Considering tuning
deterministically. Considering tuning 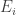 . Isolate the system from the reservoir. Tune
. Isolate the system from the reservoir. Tune 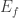 .
.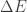 in a system’s energy comes from heat
in a system’s energy comes from heat  and/or from work
and/or from work 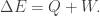 Our system hasn’t exchanged energy with any heat reservoir between the measurements. So the energy change consists of work:
Our system hasn’t exchanged energy with any heat reservoir between the measurements. So the energy change consists of work:  .
.
 .
.  denotes the probability that the next trial will require an amount
denotes the probability that the next trial will require an amount  .
.



 , would have eigenstates
, would have eigenstates  . The labels
. The labels  denote possible amounts of energy.
denote possible amounts of energy.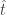 . Let
. Let  denote an eigenstate of
denote an eigenstate of 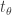 .
. to
to  . Such clocks can’t exist.
. Such clocks can’t exist. . The clock begins in a Gaussian state that peaks at one time state
. The clock begins in a Gaussian state that peaks at one time state 





 to the topology of the layers. Once we peel off all the layers, we find that for some, there is nothing left while for others, there is a nontrivial core. This observation allows us to better address the previous questions: we defined a fracton phase (one type of it) as models smoothly related to each other after adding or removing layers; the topological nature of the order is manifested in how the properties of the model are determined by the topology of the layers.
to the topology of the layers. Once we peel off all the layers, we find that for some, there is nothing left while for others, there is a nontrivial core. This observation allows us to better address the previous questions: we defined a fracton phase (one type of it) as models smoothly related to each other after adding or removing layers; the topological nature of the order is manifested in how the properties of the model are determined by the topology of the layers. The onion structure is nice, because it allows us to reduce much of the story from 3D to 2D, where we understand things much better. It clarifies many of the weirdnesses of the fracton model we studied, and there is indication that it may apply to a much wider range of fracton models, so we have an exciting road ahead of us. On the other hand, it is also clear that the onion structure does not cover everything. In particular, it does not cover Haah’s code! Haah’s code cannot be built in a layered way and its properties are in a sense intrinsically three dimensional. So, after finishing this whole journey through the onion field, I will be back to staring at Haah’s code again and wondering what to do with it, like what I have been doing in the eight years since Jeongwan’s paper first came out. But maybe this time I will have some better ideas.
The onion structure is nice, because it allows us to reduce much of the story from 3D to 2D, where we understand things much better. It clarifies many of the weirdnesses of the fracton model we studied, and there is indication that it may apply to a much wider range of fracton models, so we have an exciting road ahead of us. On the other hand, it is also clear that the onion structure does not cover everything. In particular, it does not cover Haah’s code! Haah’s code cannot be built in a layered way and its properties are in a sense intrinsically three dimensional. So, after finishing this whole journey through the onion field, I will be back to staring at Haah’s code again and wondering what to do with it, like what I have been doing in the eight years since Jeongwan’s paper first came out. But maybe this time I will have some better ideas.


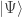 . Suppose that you measure the electron’s position. The measurement outputs one of many possible values
. Suppose that you measure the electron’s position. The measurement outputs one of many possible values  in space. Measurement devices have limited precision. You can measure the position only to within some error
in space. Measurement devices have limited precision. You can measure the position only to within some error  :
:  .
. does the measurement have of outputting some value
does the measurement have of outputting some value  ? We can calculate
? We can calculate  and
and  is a probability density, which you can think of as a set of probabilities. The density can vary with
is a probability density, which you can think of as a set of probabilities. The density can vary with  . You can likely predict the momentum measurement’s outcome.
. You can likely predict the momentum measurement’s outcome.
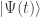 evolved in time (represented by
evolved in time (represented by  ).
).
 .
.  , analogous to 1.
, analogous to 1. analogous to position. The
analogous to position. The  -axis represents an observable
-axis represents an observable  analogous to momentum.
analogous to momentum.
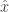 . The qubit would collapse to the state
. The qubit would collapse to the state  , represented by the arrow that points along
, represented by the arrow that points along  , represented by the opposite arrow.
, represented by the opposite arrow.
 denote an axis near
denote an axis near  and
and  .
.
 . These axes stand in for position and momentum. The state would, loosely speaking, swirl around the Bloch ball.
. These axes stand in for position and momentum. The state would, loosely speaking, swirl around the Bloch ball.






